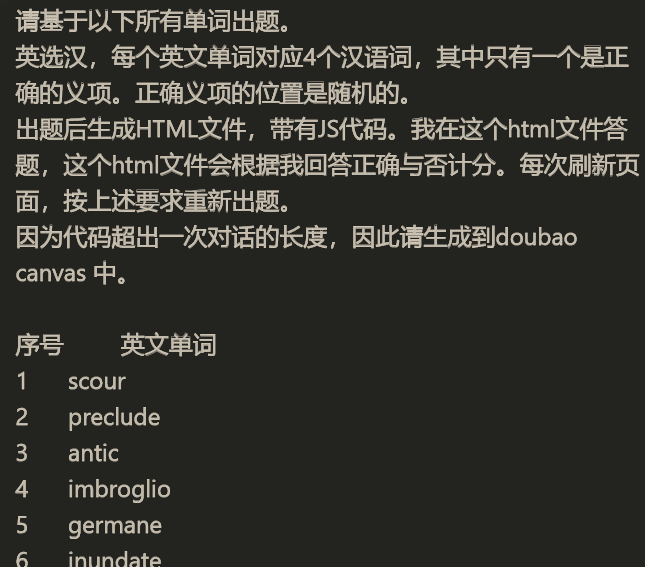
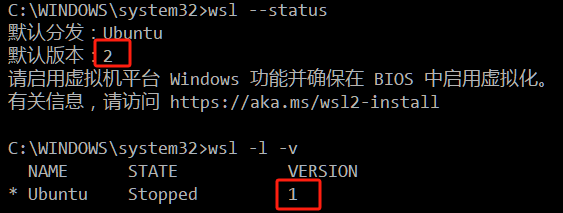
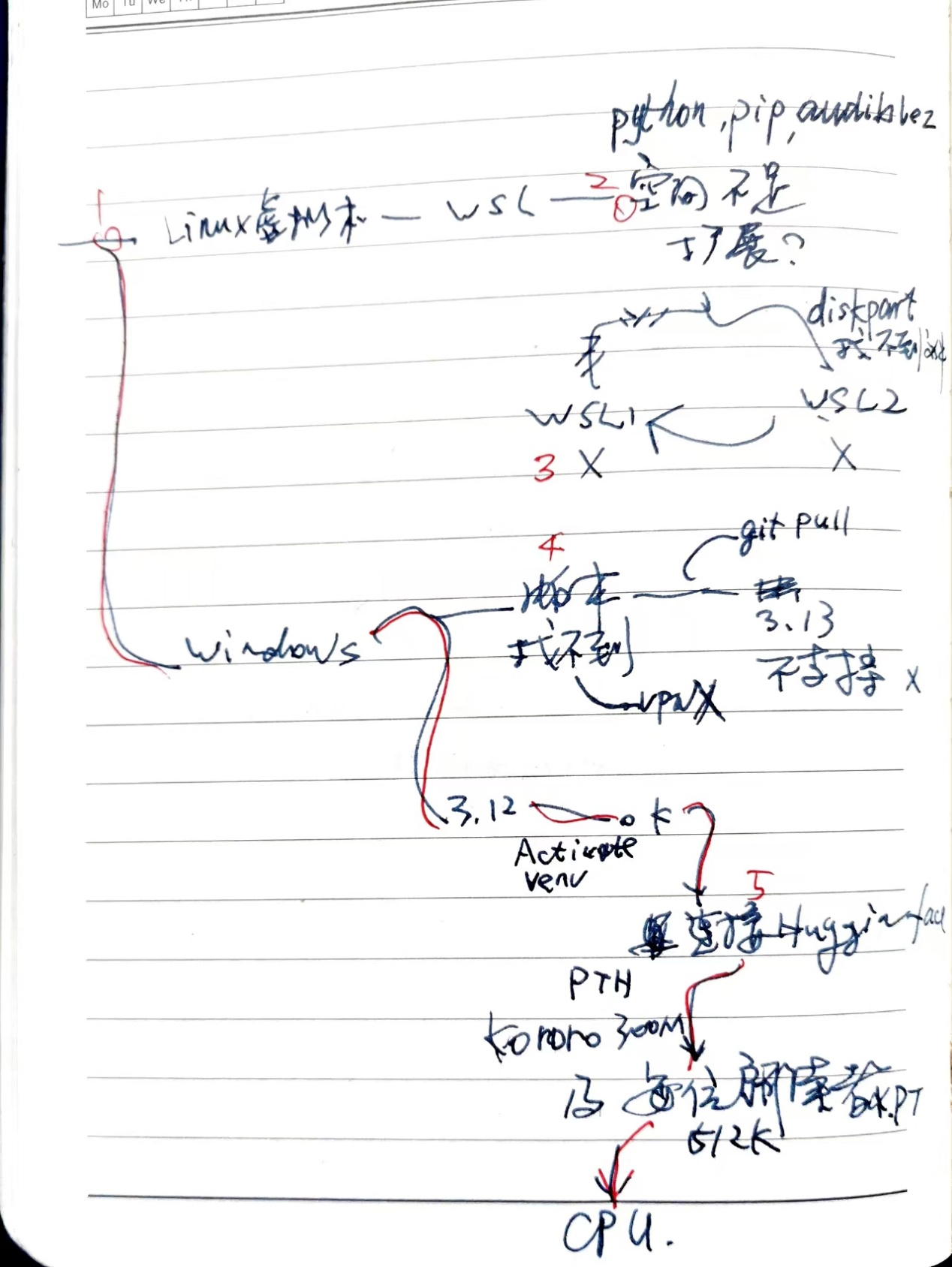
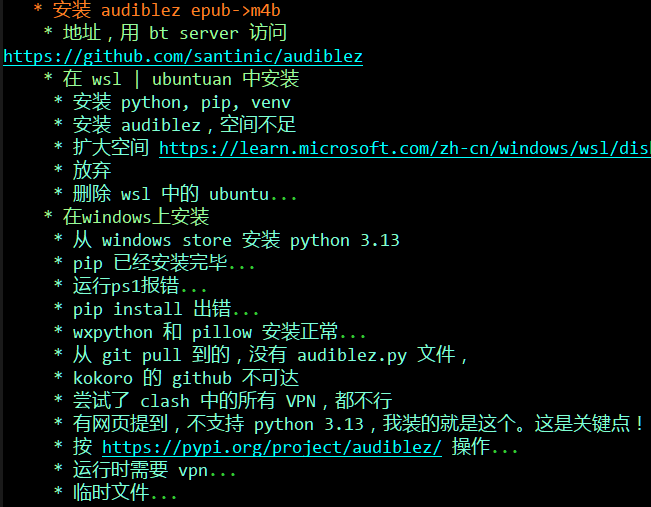
1. 好东西要跟好朋友分享
有一天,陈昕若发给我了个视频链接,附言的大意是:你看这个东西好玩啊。如下图所示。

是个时钟。每秒翻牌,kuakua响得很帅。
陈昕若说:好玩不?
我说:好玩。
陈昕若说:做一个?
我说:好。
于是我们迅速大致讨论了一下。买这么个东西,总价不会超过1000元。但是购买,多么无聊。只有亲手做一个,才有意思。
分工是,他出经费,我负责玩;他和吴晓江负责机械加工,我负责总体方案和软件和电子连线。
我每天做一点,后来把软件部分和总体设计的实施完成了。已快递给陈昕若,等他俩的精工机械,再去现场调试庆祝,老友欢聚。我的工作部分的记录整理如下。
2. 技术方案讨论
2.1 明确需求
我把B站上类似的视频都翻了一遍,看各种各样的时钟,看它们机械部分的手段,挨个记下笔记,然后和陈昕若确定哪些是他要的,哪些不是他要的。
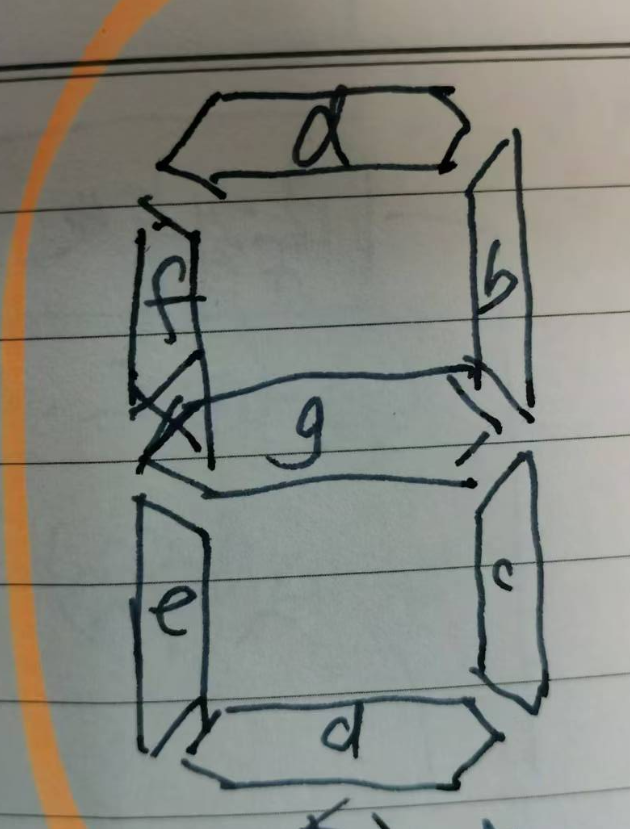
他想要的是 舵机控制时钟的笔画翻转。每个数字由八段码构成。八段码中的每个段(笔画),都由舵机控制。舵机有两个稳态的角度。舵机处于其中一个角度时,笔画与钟面平行;笔画显示出来,处于另一个角度时,笔画与钟面垂直,笔画隐藏起来。
2.2 机械部分,以及我如何临时对付
4个数字,每个数字7个笔画,共4*7=28个笔画。
每个笔画由1个舵机控制,共 28个舵机。
还需要一个框架和底板。我不需要这个,只需要把舵机放在地面上就可以。在开发的过程中,每次收起来和展开麻烦,我用一个装鸡蛋的泡沫塑料作为底板,舵机用热溶胶临时固定在上面。数字的笔画,硬纸剪出来,荧光笔涂色,用热熔胶粘到舵机的舵盘上。下图是逆,蓝色的是舵机,舵机和纸片间的白色塑料是舵盘。以下,是开发完成后的样子,讨论技术方案的时候还没有实物。

2.3 电子部分
时钟的功能有两部分。功能1.按时间走,显示时间。可以每秒动作一次,也可以每分钟动作一次。考虑到舵机不便宜,反复动作会损坏更快,所以我们采用每分钟动作一次。在调试时每秒动作一次,容易修改。功能2.设置当前时刻。
以下讨论的几种电子和软件部分的技术方案,都要满足上述两个功能。
在以下讨论中,刻意关注两个问题。1.有哪些部件,需哪些子系统的功能,如何获得。2.它们之间的连接,不仅谁和谁连接,还有连接的协议,包括不限于电平、带负载能力、编程语言的函数调用、可调试的接口 等等。
方案1 纯数字电路。用时钟发生电路产生脉冲,过时序电路的状态机得到数字的序号,经显示译码器得到八段码每个段的动作,驱动舵机调整角度。
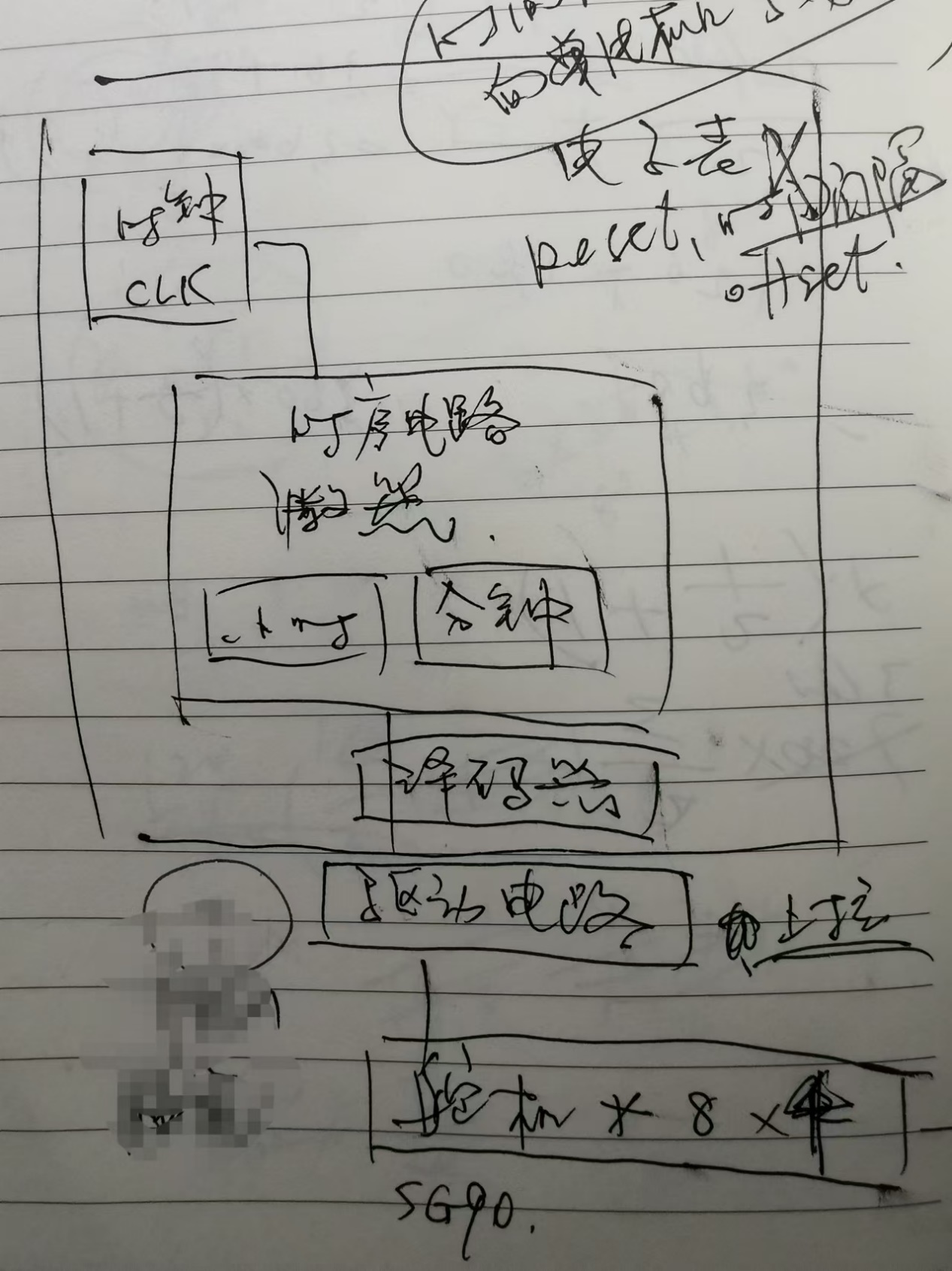
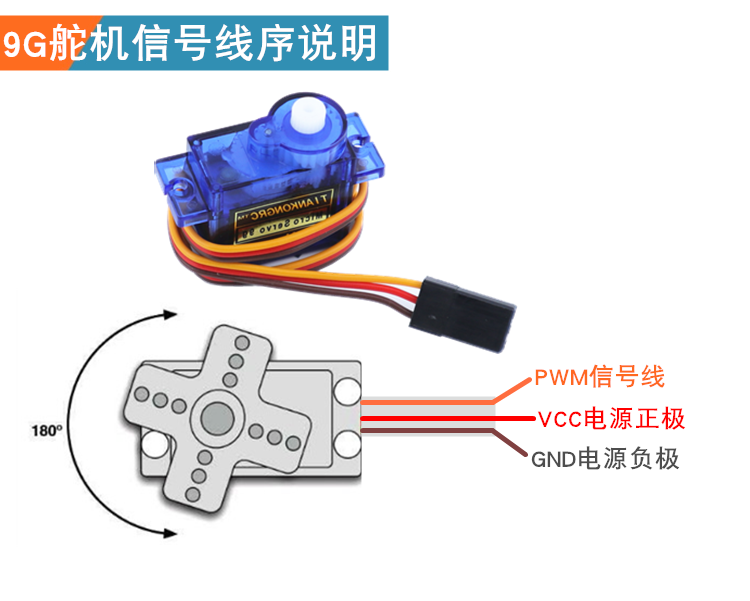
在这个方案中,时钟发生电路、时序电路、显示译码器这几个部件间的连接是TTL。你不知道TTL是什么也无所谓,我们没有采用这个方案。整个系统的其余部分和舵机之间的连接,必须遵循舵机的规范,所以要确定舵机型号,然后查手册。舵机用SG90或TS90A都可以。
说到舵机。我最初只买了七八个,构成1位数字,或者4个数字每个数字都笔画不全,先做技术原型实验。我边玩着边发视频号和朋友圈,老友龚鹏看到了。不少人看到只是觉得好玩,他不仅一眼看出来我要干啥,还快递给我一堆舵机,供物料不足之用。好人。
在这个方案中,设置时间可以靠跳线。
方案2 单片机或嵌入式系统
上面的数字电路方案涉及到不少部件,还有N多连接。想想片子小而线细就头大。想偷懒,我甚至想到,要不要拆个电子表,把LED的线引起来。想想又觉得既作弊又无聊。
舵机驱动查到了,需要用PWM。PWM是常用的信号传递手段,称作脉宽调制。你不知道PWM是什么也无所谓,虽然我们用到了,但是并不需要深入。PWM用 电压持续时间 传递信号,大致是 电压持续时间越长,舵机的角度越大。因此需要在时间分辨上达到一定精度。
这么麻烦,一定有现成的方案。查到 舵机驱动板,不止一种。由舵机驱动板负责把 角度的数值 转成PWM信号发送给舵机。
角度的数值,从系统的其他部分到舵机驱动板时,如何表示呢?查舵机驱动板的手册。有用I2C的,有用串口的,不一而足。
既然舵机驱动用了板子,而不是离散元器件,那么 时钟发生电路、时序电路、显示译码器 部分也不用保持那么纯手工的方案了吧。这三样可以一起由单片机或嵌入式系统实现。需要考虑到的是 显示译码器的输出是28个笔画,因此单片机或嵌入式系统的GPIO(你不需要知道这是具体什么,是某种输出的方法)需要足够,至少28根管脚。不,并不需要。
单片机和舵机控制板之间用I2C或者串口,取决于舵机控制板向上的规范。舵机控制板伸出至少28根线,每根线接1个舵机。

查到一款多路舵机控制板,能操控16个舵机。这样,有2个多路舵机控制板就够用,它俩之间用I2C协议级联。
正准备下单,陈昕若发给我个压缩包,他网友提供的资料。里面提到有一款32路的舵机控制板,上行用串口线。这样1个舵机控制板就够用,无须级联,并且串口线如果需要调试我也更熟悉。同时控制多个舵机,有可能电流不足,龚鹏也提醒我这一点。好在并没有同时控制32个舵机的场景。我还估算了最多同时多少个舵机动作,具体数据不到日志中查了,最终代码中也没有用到。
其余部分也如此合理,以至于接下来的电子部分完全采用了这个方案,代码我重写了一遍。重写代码的原因不是原本的代码不好,而是代码与管脚等有密切联系,即使使用原本的代码,也要读懂,并且根据硬件的连接修改。况且,写这段代码不难。所以,就重写了。
这之前,我还查了舵机的角度与PWM的占空比的关系,电平高度,周期,统统不需要。
在这个方案中,设置时间可以hardcode写在代码里。陈昕若的网友的方案里通过wifi读时间服务器,我也按这一方案,还抄了部分代码。
3. 软件部分
总的流程是
(1)通过wifi从ntp时间服务器取得时间;
(2)把时间拆成4个数字;
(3)把每个数字译码为笔画的显示或隐藏,每个数字对应7个笔画;
(4)驱动28个舵机按译码器的结果动作。
数据流为 时间 -> 数字 -> 笔画 -> 舵机。
其中时间到数字的关键是字符串处理,数字到笔画的关键是显示译码器真值表,笔画到舵机是数组元素与管脚对应。
以下按开发的过程描述,优先做技术原型,然后把技术原型拼起来。
3.1 单片机或嵌入式系统
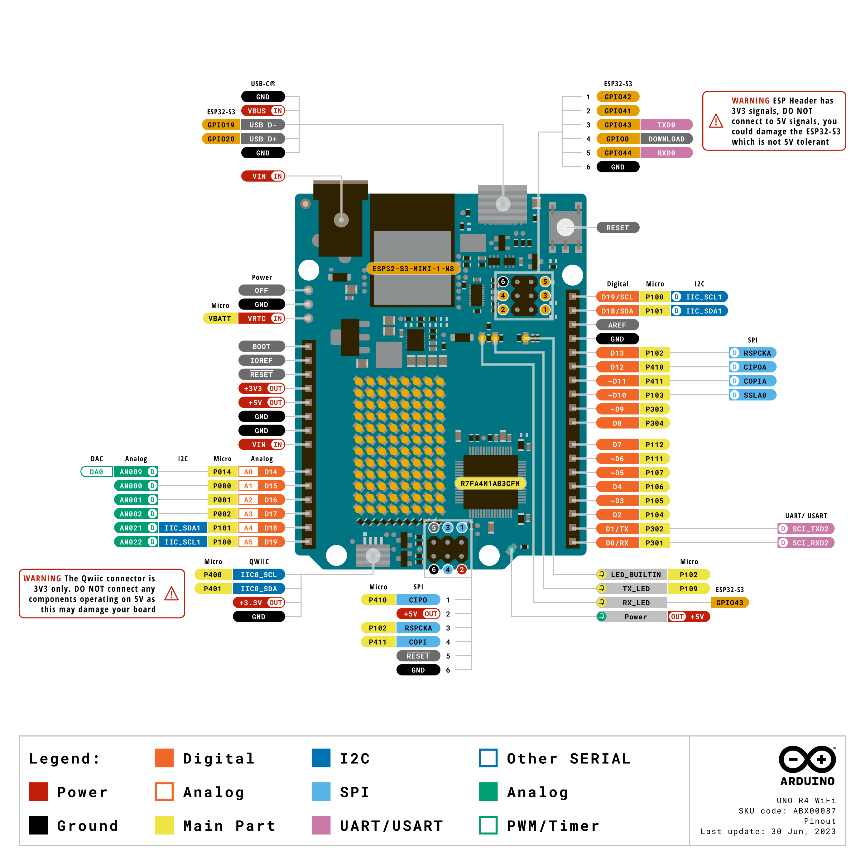
用arduino 板子  。
。
下载 arduino ide 开发环境,免安装。需要wifi和时间服务器,所以安装下面这两个库。
把 arduino板子通过USB连接到计算机,写入几段示例代码。能跑起来。
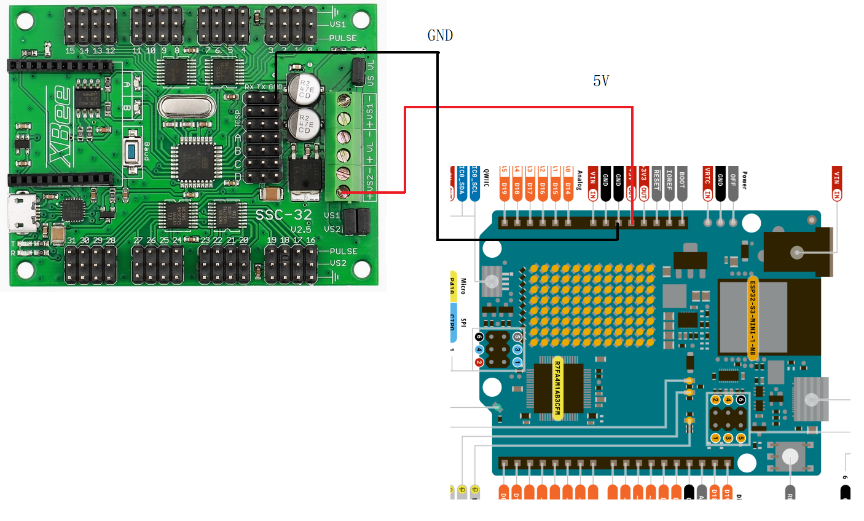
把 舵机控制板和 arduino板子连接。写几段代码,确认可以控制舵机动作。
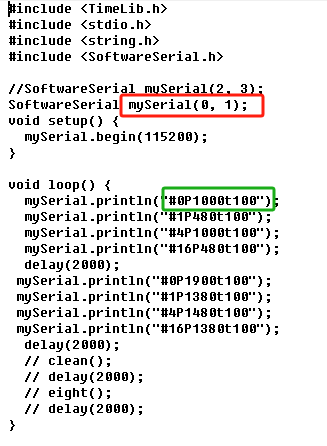
红框中的内容,与 和舵机控制板连接的arduino管脚有关。绿框中的内容,与 和特定舵机连接的舵机控制板的管脚有关。这时,没必要过度工程、过早优化,写死代码能跑通就够了。
分别写了以下几个技术原型,最后拼成第9个项目,即交付的代码。第3个项目中的2个目录,是校准舵机角度用的,也一并交付。
3.2 八段码
考虑到舵机有28个之多,一旦有某个不按期待动作,到底是软件部分,还是电子部分,还是舵机坏了,查起来麻烦。所以设置中间检测点,用arduino板上自带的LED阵列显示相同的数字。如果这个数字正常,那么软件部分无误,从舵机控制板向下检查。
LED阵列不足以显示4个数字,这个问题需要解决。
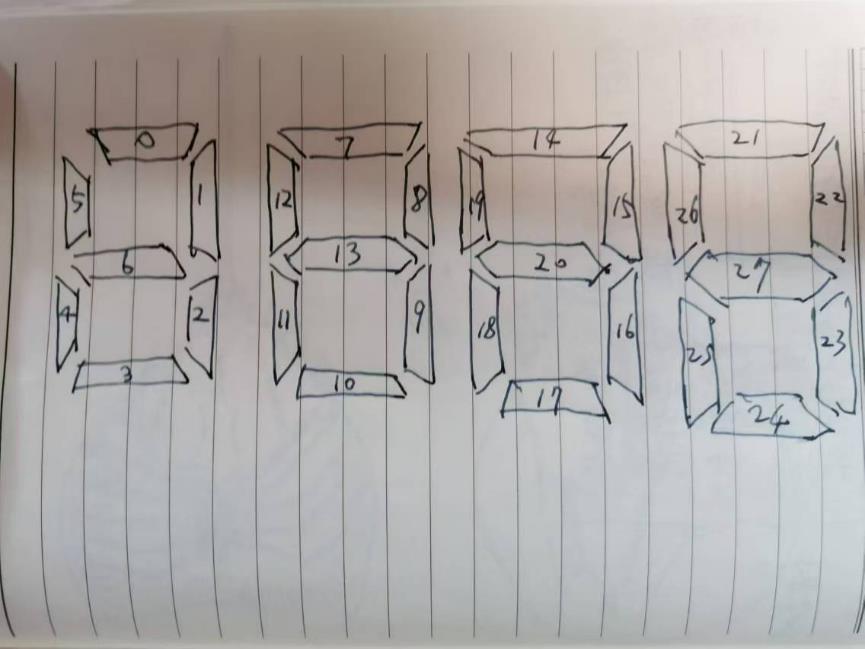
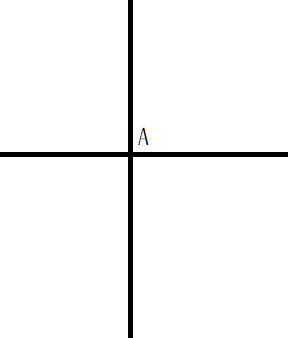
八段码的数字如下图。
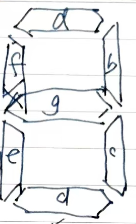
LED阵列为12*8个像素。12*8=96个像素。要显示的数字为4个,包括2位分钟、2位秒,或者2位小时、2位分钟。96个像素分给4个数字,每个数字可占24个像素=6*4。所以,八段码每个数字不得超过4*6个像素。
如果八段码的每一段用1个像素,那么高5、宽3,小于6*4个像素。如下图所示。
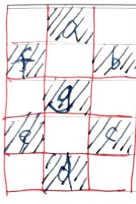
显示数字1时BC点亮,显示数字3时ABCDG点亮。看着都有些奇怪,识别困难。你可以看上图想像一下效果。
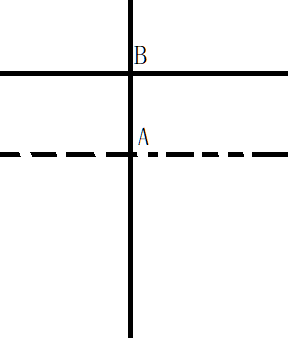
所以我设计了下面的字体。数字高5、宽4。小于6*4个像素
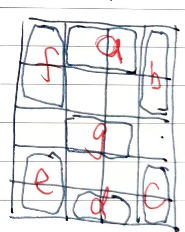
4个数字以下图的布局放置在12*8的LED阵列中。下图中的红框中是4个3中的一个。

考虑用宽3高7或高5,识别难度不高,小于6*4个像素。但是这样横向和纵向的笔画所占的像素数量不同,编程时不够统一。这一像素和笔画的映射关系弃用了。
3.3 舵机角度校准
做了两个独立的项目,一个设置所有舵机为90度,另一个设置所有舵机为0度。事实上,这两个角度并非真实的。舵机可以旋转360个角度,我只是随便选了相互垂直的两个角度,即下图中红框中的2000和1000。
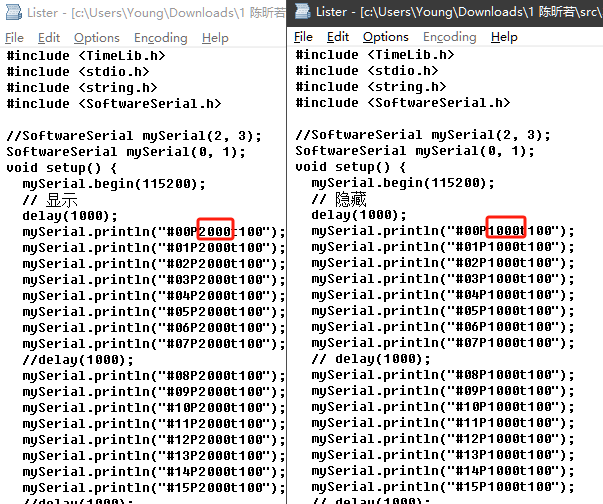
舵盘可以拔下来再插上。所以,校准时,先把舵盘拔下来。运行程序,把所有舵机设置到相同角度,比如2000,即0度。把舵盘按0度插到舵机上。再运行另一个程序,把所有舵机设置到相同角度,比如1000,即90度。检验舵盘旋转的方向是正确的。
在这之前,几乎没有代码量,连循环都不必考虑。
3.4译码器
译码器有两个。其中一个用于数字到舵机。另一个用于数字到LED阵列,调试用。
(1)数字到舵机
译码器的输入是1个数字,输出是8段码(使用其中的7段)中每一段的布尔值。如下表所示。
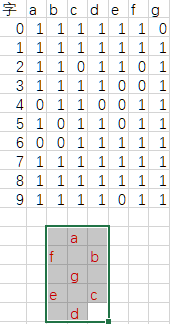
这是数字电路课程中的重要内容和重要实验,在此不赘述。
在代码实验中,把上面的表格抄成下面的数组。
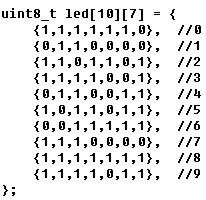
在excel中转置,复制粘贴,用emacs之类的工具加逗号。这样速度快,并且不会错。
以上是数据,以下是驱动。

上述代码实现函数,输入是1个数字,输出是8段码(使用其中的7段)中每一段的布尔值。实现方案是查表,就上上段代码中的表格。
(2)数字到LED阵列
下面这个表格是我工作的过程,手动在excel中操作的。从第一步阵列的布局到第四步代码中的平行数组。
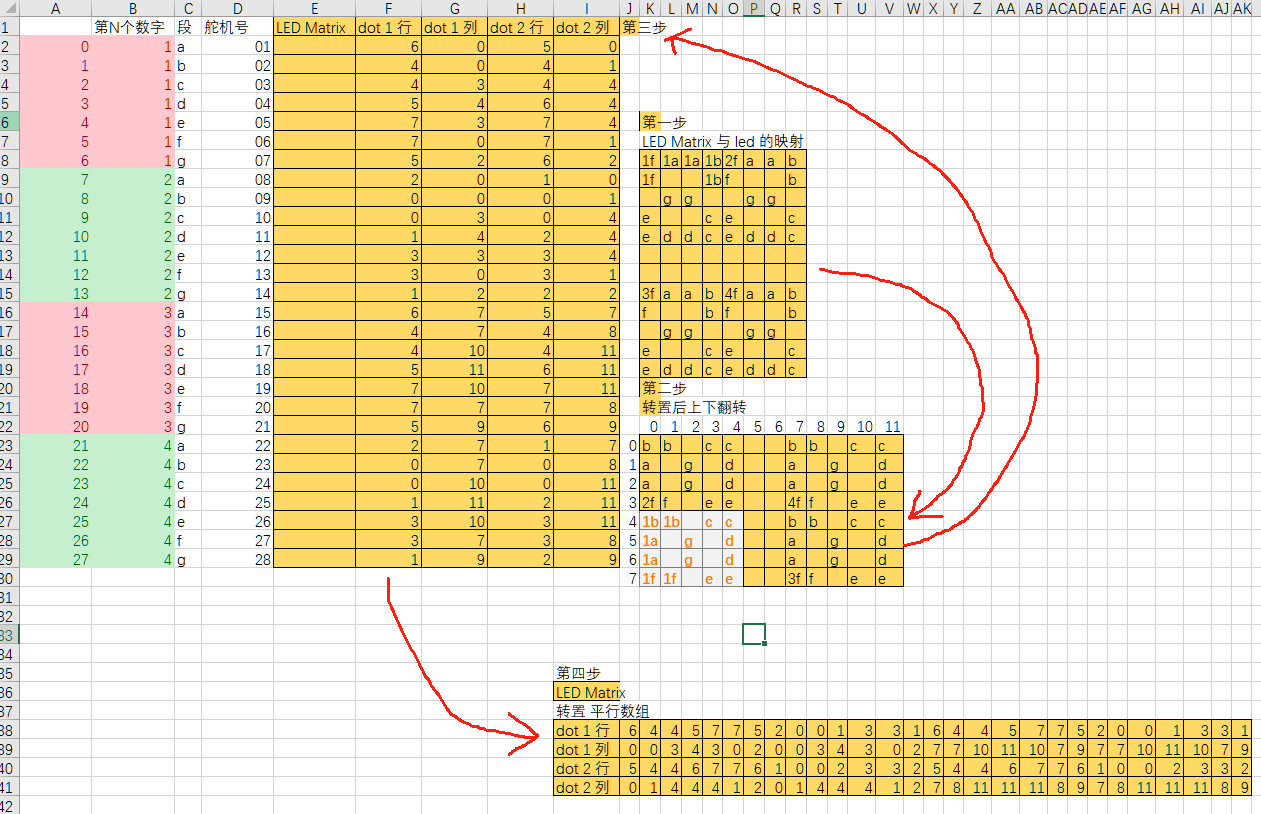
第一步是LED矩阵的布局,纵12横8,我在左上、右上、左下、右下分别放置了1个数字。
第二步转置和上下翻转,得到与arduino的 led阵列库提供的代码中,访问led阵列 grid 的坐标一致。
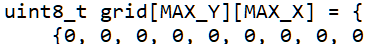
第三步 把led点阵对应到于每个数字的笔画2个像素。即每个数字的笔画对应2个像素 (dot1, dot2);每个像素有行列两个坐标,所以 dot1像素有 dot1行、dot1列,dot2像素有 dot2行、dot2列。
第四步 转置得到4个平行数组,加上逗号,抄到代码里,如下。

以上是数据,以下是驱动。

功能是 输入是4个数字,如12点34分,12:34,输入为1,2,3,4。
实现为
先用decode解码,由数字得到八段码的布尔值;
然后在循环中遍历7个笔画,每个笔画均转换到led点阵grid 中的2个像素
grid[dot1列][dot1行]=笔画
grid[dot2列][dot2行]=笔画
这是4个数字中的一个。这段代码我又抄了3遍,每遍分别输入 d2,d3,d4。这样完成4个数字到LED点阵的转换。
3.5 串口调试
按如下代码,当arduino板子连接计算机时,会通过USB仿真串口向上输出。输出结果在arduino IDE或者 COM Debug (8无1) 中都能看到。
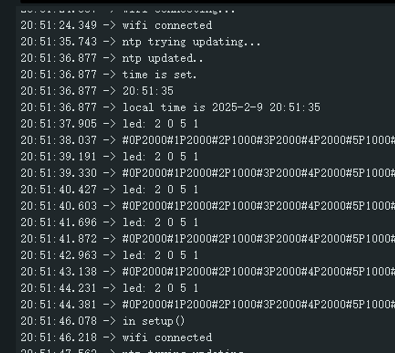
以下截屏与上述代码不对应,是反复读取时间的输出。仅作为示例帮助你了解串口输出的样子。
3.6 取时间
取决于网络环境,有时候远程的时间服务器不可达,看运气,没规律。多重复几次直到取到为止。取到时间以后,置本地时间,以后从本地取当前时间。
(1)取NTP服务器时间
略,参见后文中的源代码部分。参考和部分复制了陈昕若的网友的代码。
(2)取本地时间
以下代码,把当前时间设置为 2025年1月29日14:2:11。之后,本地时间会自己走,用now()取出。得到小时、分、秒,通过串口上传给计算机。每秒上传1次。

3.7 舵机与管脚的对应
舵机号 与 第几个数字、数字的笔画 的对应关系如下表所示。
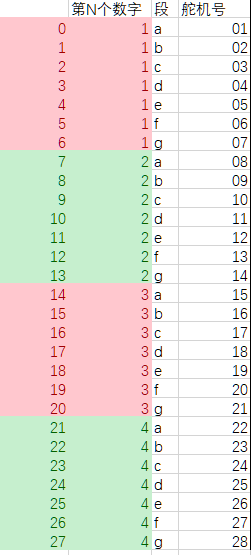
下述代码,是上面的表格转置后加上逗号。

下述代码,数组下标是译码器的出口,与第几个数字和笔画对应;数组的值是舵机的管脚号。
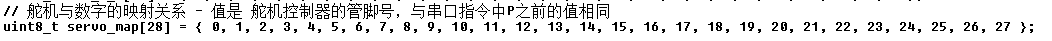
在下述代码中,4个数字中的每一个,都经过译码得到 seg笔画,然后seg的布尔值用于设置舵机的管脚。
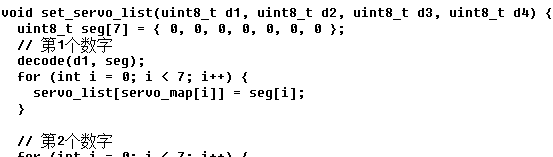
以上是数组,以下是驱动。
在下述代码中,遍历舵机列表,设置每个舵机对应的管脚的电压。我考虑过优化,只设置其中变动的那些。后来发现,即使这样,板子的电流也仍然不够。外接电源以后,无须优化,电流也足够。

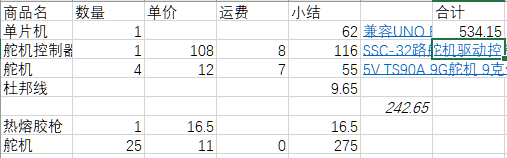
附录 物料清单
附录 机械部分
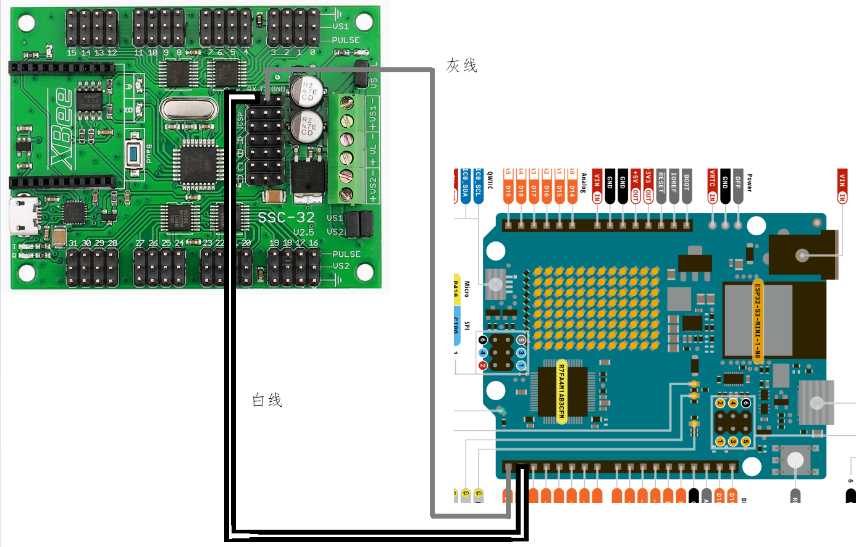
以下两张照片,分别是正面和背面。舵机在正面,线通过 过孔 到背面。两块板子都在背面,蓝色那个是arduino板子,绿色那个是舵机控制板。


在背面有一段杜邦线延长了,在蓝色arduino板子右边。并非线不够长,而是为了测试确认延长线以后信号可以传输。
附录 电子(硬件)部分
参见部署手册。
附录 代码
(1)烧写到板子里的,共252行。
//- 反复取时间 - 4个数字 - 译码为28个笔画 - 驱动 led - 驱动舵机
#include <SoftwareSerial.h>
#include <NTPClient.h>
#include <WiFiS3.h>
#include <WiFiUdp.h>
#include <TimeLib.h>
#include "Arduino_LED_Matrix.h"
//------------------------------
// Time
const char *ssid = "young huawei"; ///你家wifi名字
const char *password = "younggift"; //你家wifi密码
//------------------------------
// LED,板载led矩阵
// grid dimensions. should not be larger than 8x8
#define MAX_Y 8
#define MAX_X 12
// 0 is dark, 1 is live bright
uint8_t grid[MAX_Y][MAX_X] = {
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
};
ArduinoLEDMatrix matrix;
// LED点阵与数字的映射关系
// 每1个笔画/段对应2个led点阵的像素
// dot_1_y 第1个像素的纵坐标
// dot_1_x 第1个像素的横坐标
// dot_2_y 第2个像素的纵坐标
// dot_2_x 第2个像素的横坐标
// 数组下标 是笔画/段。每个数字有7段,共7段*4个数字
// 数值的值 是在led矩阵上的坐标
uint8_t dot_1_y[28] = { 6, 4, 4, 5, 7, 7, 5, 2, 0, 0, 1, 3, 3, 1, 6, 4, 4, 5, 7, 7, 5, 2, 0, 0, 1, 3, 3, 1 };
uint8_t dot_1_x[28] = { 0, 0, 3, 4, 3, 0, 2, 0, 0, 3, 4, 3, 0, 2, 7, 7, 10, 11, 10, 7, 9, 7, 7, 10, 11, 10, 7, 9 };
uint8_t dot_2_y[28] = { 5, 4, 4, 6, 7, 7, 6, 1, 0, 0, 2, 3, 3, 2, 5, 4, 4, 6, 7, 7, 6, 1, 0, 0, 2, 3, 3, 2 };
uint8_t dot_2_x[28] = { 0, 1, 4, 4, 4, 1, 2, 0, 1, 4, 4, 4, 1, 2, 7, 8, 11, 11, 11, 8, 9, 7, 8, 11, 11, 11, 8, 9 };
// 设置 led 矩阵,参数是4个数字
void set_led_matrix(uint8_t d1, uint8_t d2, uint8_t d3, uint8_t d4) {
// 第1个数字
uint8_t seg[7] = { 0, 0, 0, 0, 0, 0, 0 }; //当前数字的7个段/笔画
decode(d1, seg);
for (int i = 0; i < 7; i++) {
grid[dot_1_y[i]][dot_1_x[i]] = seg[i];
grid[dot_2_y[i]][dot_2_x[i]] = seg[i];
}
// 第2个数字
for (int i = 0; i < 7; i++) {
seg[i] = 0;
}
decode(d2, seg);
for (int i = 0; i < 7; i++) {
grid[dot_1_y[i + 7]][dot_1_x[i + 7]] = seg[i];
grid[dot_2_y[i + 7]][dot_2_x[i + 7]] = seg[i];
}
// 第3个数字
for (int i = 0; i < 7; i++) {
seg[i] = 0;
}
decode(d3, seg);
for (int i = 0; i < 7; i++) {
grid[dot_1_y[i + 2 * 7]][dot_1_x[i + 2 * 7]] = seg[i];
grid[dot_2_y[i + 2 * 7]][dot_2_x[i + 2 * 7]] = seg[i];
}
// 第4个数字
for (int i = 0; i < 7; i++) {
seg[i] = 0;
}
decode(d4, seg);
for (int i = 0; i < 7; i++) {
grid[dot_1_y[i + 3 * 7]][dot_1_x[i + 3 * 7]] = seg[i];
grid[dot_2_y[i + 3 * 7]][dot_2_x[i + 3 * 7]] = seg[i];
}
}
void displayGrid() {
matrix.renderBitmap(grid, 8, 12);
}
//-----------------------------------------
// 数字七段码
const uint8_t led[10][7] = {
{ 1, 1, 1, 1, 1, 1, 0 }, //0
{ 0, 1, 1, 0, 0, 0, 0 }, //1
{ 1, 1, 0, 1, 1, 0, 1 }, //2
{ 1, 1, 1, 1, 0, 0, 1 }, //3
{ 0, 1, 1, 0, 0, 1, 1 }, //4
{ 1, 0, 1, 1, 0, 1, 1 }, //5
{ 1, 0, 1, 1, 1, 1, 1 }, //6
{ 1, 1, 1, 0, 0, 0, 0 }, //7
{ 1, 1, 1, 1, 1, 1, 1 }, //8
{ 1, 1, 1, 1, 0, 1, 1 }, //9
};
void decode(uint8_t digital, uint8_t *seg) {
for (int i = 0; i <= 7; i++) {
seg[i] = led[digital][i];
}
}
//-----------------------------
// 舵机
// 舵机与数字的映射关系 - 值是 舵机控制器的管脚号,与串口指令中P之前的值相同
uint8_t servo_map[28] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27 };
// 当前舵机的状态
uint8_t servo_list[28] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
// 驱动舵机动作,参数是4个数字
void set_servo_list(uint8_t d1, uint8_t d2, uint8_t d3, uint8_t d4) {
uint8_t seg[7] = { 0, 0, 0, 0, 0, 0, 0 };
// 第1个数字
decode(d1, seg);
for (int i = 0; i < 7; i++) {
servo_list[servo_map[i]] = seg[i];
}
// 第2个数字
for (int i = 0; i < 7; i++) {
seg[i] = 0;
}
decode(d2, seg);
for (int i = 0; i < 7; i++) {
servo_list[servo_map[i + 7 * 1]] = seg[i];
}
// 第3个数字
for (int i = 0; i < 7; i++) {
seg[i] = 0;
}
decode(d3, seg);
for (int i = 0; i < 7; i++) {
servo_list[servo_map[i + 7 * 2]] = seg[i];
}
// 第4个数字
for (int i = 0; i < 7; i++) {
seg[i] = 0;
}
decode(d4, seg);
for (int i = 0; i < 7; i++) {
servo_list[servo_map[i + 7 * 3]] = seg[i];
}
}
// 与舵机控制板通信的串口
SoftwareSerial mySerial(0, 1);
// 驱动舵机动作
void actServo() {
// mySerial.println("#00P2000t100");
// 与舵机控制板串口通信的指令,除以下各值外,其余不变
// 00 是 管脚号,取值[0,31]
// 2000 是角度对应的占空比/2000us,取值[50,2500],需要根据舵机安放角度校准
// 100 是完成动作花费的时间,这里是100毫秒
// 可以多个管脚共用同一个t值
String s = "";
for (int i = 0; i < 28; i++) {
//mySerial.print("#" + i);
s = s + "#" + i;
if (servo_list[i] == 0) { //#00P
//mySerial.print("P1000"); // 隐藏
s = s + "P1000";
} else {
//mySerial.print("P2000"); // 显示
s = s + "P2000";
}
}
//mySerial.println("t100");
s = s + "t100";
mySerial.println(s); //舵机动作
Serial.println(s); // debugging
}
//=====================================================================
//------------------------------
void setup() {
// put your setup code here, to run once:
// 反复取npt时间,直到成功
// 调试用, 连接 pc arduino ide
Serial.begin(9600);
Serial.println("in setup()");
// wifi
WiFi.begin(ssid, password);
while (WiFi.status() != WL_CONNECTED) {
delay(500);
Serial.println("wifi connecting...");
}
Serial.println("wifi connected");
// ntp
WiFiUDP ntpUDP;
NTPClient timeClient(ntpUDP, "pool.ntp.org", 60 * 60 * 8, 500);
timeClient.begin();
while (timeClient.update() != true) {
Serial.println("ntp trying updating...");
delay(500);
}
Serial.println("ntp updated..");
while (timeClient.isTimeSet() != true) {
Serial.println("time is setting...");
delay(500);
}
Serial.println("time is set.");
Serial.println(timeClient.getFormattedTime());
// 把npt时间设置为本地时间
time_t epochTime = timeClient.getEpochTime();
struct tm *ptm = gmtime((time_t *)&epochTime);
setTime(ptm->tm_hour, ptm->tm_min, ptm->tm_sec, ptm->tm_mday, ptm->tm_mon + 1, ptm->tm_year + 1900);
time_t t = now();
int h = hour(t);
int m = minute(t);
int s = second(t);
String ss = "local time is ";
Serial.println(ss + year(t) + "-" + month(t) + "-" + day(t) + " " + h + ":" + m + ":" + s);
// led 矩阵
matrix.begin();
// 与舵机控制板通信
mySerial.begin(115200); //舵机控制器
}
void loop() {
// put your main code here, to run repeatedly:
// 每秒一次,取本地时间
delay(1000);
time_t t = now();
// 把时间转换并分割为 hh-mm-ss
int h = hour(t);
int m = minute(t);
int s = second(t);
// 把 hh-mm 转换为4个数字
// h/10, h%10, m/10, m%10, s/10, s%10
uint8_t d1 = h / 10;
uint8_t d2 = h % 10;
uint8_t d3 = m / 10;
uint8_t d4 = m % 10;
// 或
// 调试用 把 mm-ss 转换为4个数字
// uint8_t d1 = m / 10;
// uint8_t d2 = m % 10;
// uint8_t d3 = s / 10;
// uint8_t d4 = s % 10;
// 驱动 led 动作,内含 把4个数字译码为 28个笔画
set_led_matrix(d1, d2, d3, d4);
displayGrid();
String ss = "led: ";
Serial.println(ss + d1 + " " + d2 + " " + d3 + " " + d4);
// 驱动舵机 set_led_matrix();
//set_servo_list(d1, d2, d3, d4);
set_servo_list(d1, d2, d3, d4);
actServo();
}
(2)校准舵机角度 之一,另一个角度从略
#include <TimeLib.h>
#include <stdio.h>
#include <string.h>
#include <SoftwareSerial.h>
//SoftwareSerial mySerial(2, 3);
SoftwareSerial mySerial(0, 1);
void setup() {
mySerial.begin(115200);
// 显示
delay(1000);
mySerial.println("#00P2000t100");
mySerial.println("#01P2000t100");
mySerial.println("#02P2000t100");
mySerial.println("#03P2000t100");
mySerial.println("#04P2000t100");
mySerial.println("#05P2000t100");
mySerial.println("#06P2000t100");
mySerial.println("#07P2000t100");
//delay(1000);
mySerial.println("#08P2000t100");
mySerial.println("#09P2000t100");
mySerial.println("#10P2000t100");
mySerial.println("#11P2000t100");
mySerial.println("#12P2000t100");
mySerial.println("#13P2000t100");
mySerial.println("#14P2000t100");
mySerial.println("#15P2000t100");
//delay(1000);
mySerial.println("#16P2000t100");
mySerial.println("#17P2000t100");
mySerial.println("#18P2000t100");
mySerial.println("#19P2000t100");
mySerial.println("#20P2000t100");
mySerial.println("#21P2000t100");
mySerial.println("#22P2000t100");
mySerial.println("#23P2000t100");
// delay(1000);
mySerial.println("#24P2000t100");
mySerial.println("#25P2000t100");
mySerial.println("#26P2000t100");
mySerial.println("#27P2000t100");
mySerial.println("#28P2000t100");
mySerial.println("#29P2000t100");
mySerial.println("#30P2000t100");
mySerial.println("#31P2000t100");
}
void loop() {
delay(1000);
mySerial.println("#00P2000t100");
mySerial.println("#01P2000t100");
mySerial.println("#02P2000t100");
mySerial.println("#03P2000t100");
mySerial.println("#04P2000t100");
mySerial.println("#05P2000t100");
mySerial.println("#06P2000t100");
mySerial.println("#07P2000t100");
delay(1000);
mySerial.println("#08P2000t100");
mySerial.println("#09P2000t100");
mySerial.println("#10P2000t100");
mySerial.println("#11P2000t100");
mySerial.println("#12P2000t100");
mySerial.println("#13P2000t100");
mySerial.println("#14P2000t100");
mySerial.println("#15P2000t100");
delay(1000);
mySerial.println("#16P2000t100");
mySerial.println("#17P2000t100");
mySerial.println("#18P2000t100");
mySerial.println("#19P2000t100");
mySerial.println("#20P2000t100");
mySerial.println("#21P2000t100");
mySerial.println("#22P2000t100");
mySerial.println("#23P2000t100");
delay(1000);
mySerial.println("#24P2000t100");
mySerial.println("#25P2000t100");
mySerial.println("#26P2000t100");
mySerial.println("#27P2000t100");
mySerial.println("#28P2000t100");
mySerial.println("#29P2000t100");
mySerial.println("#30P2000t100");
mySerial.println("#31P2000t100");
}
附录 部署手册
参见下一篇博客。
此文也发布在以下站点。
----
知乎 https://www.zhihu.com/people/yang-gui-fu-52
独立博客 https://younggift.net/
微信公众号 杨贵福
----
以下是我曾经发布博客的站点,有些旧文。
----
豆瓣 - 因为审核"我的日记",不再更新。
https://www.douban.com/people/younggift/?_i=0098558fqLUL9h
CSDN – 因为要求我登记手机号码的原因是“为了您的安全”,不再更新。
https://blog.csdn.net/younggift?type=blog
blogsopt – 因为从我的机器不可达,无法更新