可调节哑铃片的一对哑铃,发现份量不对。经过称量和讨论,确定了折算公式,缺1/4。
1. 偶然发现
一对哑铃,2根杆,4个锁紧螺丝;哑铃片共4种不同份量,每种4个。4种哑铃片分别标称2.5kg、2kg、1.25kg、0.75kg。组合出不计杆每只 (2+1.25+0.75)*2 =8kg,兴致勃勃练了一段时间。觉得小有进步,可以调高份量了。

忘了因为什么,可能是想把杆重算进去,也可能为了方便以前一直用的固定重量哑铃对比,总之偶然想到称重一下。不称要不紧,一称发现份量不对,缺斤少两。
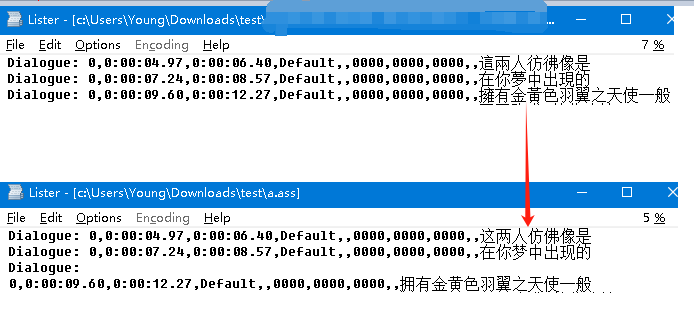
如下两图所示,标称750g的,称重结果为431g;标称1.25kg的,称重808kg。标称相同的4个哑铃片重量上下略有浮动,十几或几十克,容易理解。但是标称与称重结果差距这么大,就没法用误差解释了。


我锻炼的时候写日志,要记录重量。以后吹牛时,哑铃片的份量也得如实才行啊。不然,在家里举8kg,在别的地方别人面前一显摆,8kg根本举不起来,岂不尴尬。哑铃仅仅重量不准,毕竟这么沉重,又不能扔了,那么想办法找到真实重量标定一下吧。
2. 猜测
猜测上面写的数字的单位不是kg,而是磅,这个重小的重量单位。
换算了一下,手头现有的数字不符合磅和公斤的换算关系。
| 标称 | 称重(g) |
| 0.75 | 443 |
| 1.25 | 808 |
在网上查到 https://forum.xitek.com/thread-1772754-1-1.html 在 bing 的 cache 中,PCM120说的情况跟我的差不多。
: 我的哑铃用了将近有二十年了,一直没注意重量是否符合要求,当年是按重量付款的,价格约为5元/千克。
: 看了楼主的帖子,下午把哑铃也称了一下,结果如下(标称/实际 单位 :千克):
: 哑铃片:0.75 / 0.49 1.50 / 0.976 2.0 / 1.495。
: 附件重量(手柄及两个固定螺母):1.329千克。
盎司?也不对。
以前见过向龙的壶铃只有数字,没有单位,也好奇过是磅还是公斤。后来用称重确认了,所以还是用秤吧,别猜了。
3. 称重
最简单的称重方法是,4种、每种4个,共16个哑铃片,每个称重一下,贴个不干胶贴标上数值。但是我的工具不行。
我手头现有两个秤。一个是厨房用秤,如上两图所示。量程/最大1kg,精度0.1g。另一个是体重秤(此刻才想到体重秤有两个,但是不影响接下来的方法和结论)。最大重量不清楚,能称大活人,精度也不精楚。最大重量远超过我要称重的哑铃片、杆、螺丝的总和,但是量程不仅是最大重量,还包括最小重量,与精度又有不同。说起细节来挺麻烦,简而言之,从现象上看,哑铃片放在体重秤上“打不起砣”,显示为0。

解决方案是这样的。
(1) 人先站在体重秤上,作为空白。体重秤没有“去皮”功能,所以记录下这个重量,称为H。接着,人拿着哑铃片D,称得新的重量N。计算,哑铃片的重量D=N-H。
(2) 小的哑铃片按上述方法称重得到0,因为体重秤的精度不够。所以用厨房秤称。
(3) 大的和小的之间的重量,比如空杆,人和体重秤联合测量,得到结果0,又超出厨房秤的范围。在厨房秤旁边搭个差不多等高的小台子,把重物同时放在小台子和厨房秤上,得到一侧的读数L。把重物旋转180度,测另一侧的读数R。L+R得到空杆的重量1kg多一点。
以上方案中包括以下假设和需要讨论的地方。
(1) 根据现象,可以推得体重秤的误差分布是不均匀的。因为,在0附近,测得存在哑铃片和不存在哑铃片间的差额为0;在人体重附近,这个差额不是0。既然误差分布不均匀,那么在哪个范围内误差是可忽略的。
(2) 记录数据时假设了体重秤和厨房秤的误差相同。更有甚者,假设了如果二者量程无限,那么同一重物在这两个秤上的结果相同,不然无法比较或求和。有同学可能提到,都是法定用于计量的秤,应该不会有问题吧。如果以此为依据,那么哑铃上还标着数字呢,也作不得准。
(3) 印象里方案(3)中的称量方法对重物放得有多平是有要求的,但是细节不记得了,人懒没有查。所以,假设两次称量之和就是准确的重量。
称了几个组合,得到一些数字。笔记粗糙而乱,除了记录还有猜测和推算(以及暴露口算和笔算能力有多么弱)。下面有表格,此处仅展示,可跳过,不影响阅读。 
4. 拟合
实验得到以下几组数据。之所以有斤,还有kg,是因为体重称有时候单位是公斤(kg),有时候是斤。这样记录保留了原始数据,虽然没有表明哪个才是原始的。
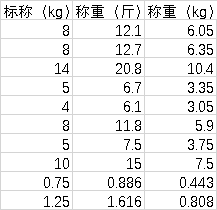
在测量过程中,我就开始猜测,感觉像是 哑铃片实际重量为标称的3/4。所以在笔记的左侧用测得的其他数据验证了一下,感觉差不多。这可以作为一个结论,即3/4不知道从哪里来的,经验公式。
不过经验公式不够“科学”,说服力还可以更强一些。我把这些数据用XY散点图绘图,如下图所示。再拟合一下,Excel中称为 趋势线。
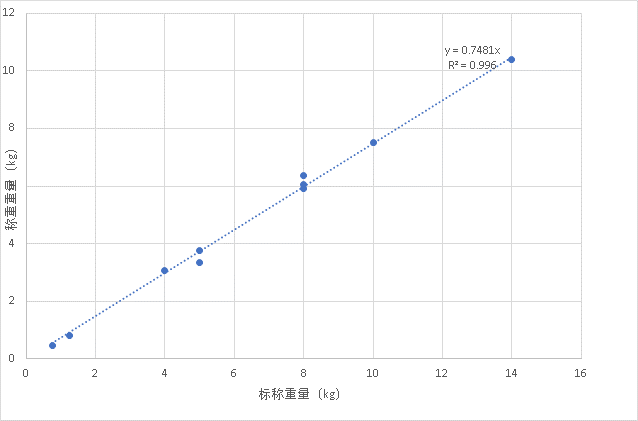
拟合的结果是公式的参数。用于拟合的数据有了,先验公式/曲线的函数是什么呢?我们可以通过观察发现,差不多是线性的。也可以猜测一下缺斤少两的做法,在什么情况下不易被用户发现。缺斤少两的直接收益是厂商可以用更少的铁,毕竟哑铃价格中的重要因素是铁的价格。如果每个哑铃减去相同的重量,对较高重量的哑铃获益不多,在较低重量的哑铃上更容易暴露出来。那么按标称乘以一个因数,即线性的缺斤少两,是更佳方案。线性的结果拟合的就挺好,更复杂的,就略过不讨论了。
从图示和R2上都可以看出,线性拟合对于所有数据的误差都不大。
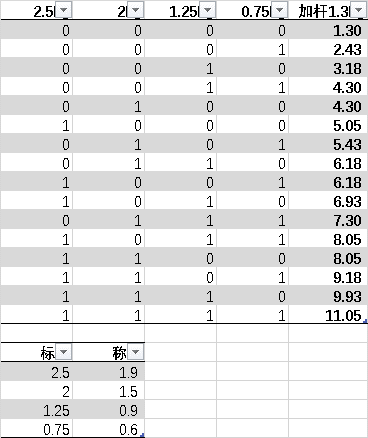
所以,得出结论 标称重量*3/4 或者 标称重量*0.75,即哑铃片的真实重量。缺1/4。以前的哑铃片组合表格,修订如下。我以为去杆8kg的,加杆和螺丝以后,刚好8kg多一点。
5. 讨论
为什么追究这个问题呢,一个因素当然是考虑在工具有限的情况下如何得到有说服力并且易用的结果,是件好玩的事。
也有更实际点的用途。网上有报道,有人在家里用哑铃或杠铃锻炼,以为自己厉害到这个数值了,结果在健身房举了真实重量的哑铃,导致受伤了。
邢ZP老师提到,有百米跑道只有九十米,比实际短十米。受测小朋友误以为自己是天赋异秉不可多得的短跑人才,长期为没能在奥运会上为国争光而遗憾。直到后来这位同学家乡的新闻爆出体育设施建设中的贪污才让他终于把心放下。
我们讨论到,哑铃不是计量器具,不能当作法码用,所以缺斤少量不受计量法管束吧。邢ZP老师还提到,计量器具里,健身房的体重秤的数值说不定也有偏。不过,体重秤并不用于称肉卖,所以并没有顾客多花钱少得肉,没有这方面的损失,还得到了情绪价值。这个,又怎么看呢?
https://www.zhihu.com/people/yang-gui-fu-52
微信公众号 杨贵福