某天,长春市发布了疫情数据,内容相当长,而格式有规格。所以我想到用正则表达式抽取出来,看着方便一些。
1. 原始数据,特征,正则表达式

原始数据有很多行,看起来形式大概这样。
: 新增确诊病例:
: 确诊病例1-35:现住九台区。系确诊病例的密切接触者,隔离期间核酸检测阳性,3月11日转入长春市传染病医院,诊断为确诊病例。
: 新增无症状感染者:
: 无症状感染者1-47:现h住九台区。系无症状感染者的密切接触者,隔离期间核酸检测阳性,3月11日被确定为无症状感染者。
: 无症状感染者48-63:现住九台区。系确诊病例的密切接触者,隔离期间核酸检测阳性,3月11日转入长春市传染病医院,被确定为无症状感染者。
能够看到明显的规律:
(1)数据由若干 行 组成;
(2)在每行中,需要提取的数据有共同特征,
比如下面这一行。
> 确诊病例1-35:现住九台区。系确诊病例的密切接触者,隔离期间核酸检测阳性,3月11日转入长春市传染病医院,诊断为确诊病例。按原文与特征的对比如下。
| 原文 | 特征 |
| 无症状感染者1-47:现 | 不需要的任意字符序列... |
| 住 | 住 |
| 需要的任意字符序列... | 九台区 |
| 。 | '。' |
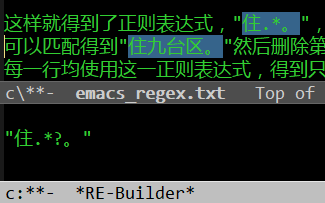
| 系无症状感染者的密切接触者,隔离期间核酸检测阳性,3月11日被确定为无 | 症状感染者。|不需要的任意字符序列... |这样就得到了正则表达式,"住.*。",可以匹配需要的字符序列。比如上面这行,可以匹配得到"住九台区。"然后删除第一个字和最后一个字,得到"九台区"。对每一行均使用这一正则表达式,得到只有符合匹配要求的字符串。整行中都不符合特征的,这一行不会被选出来。
正则表达式可以用 命令行工具grep,程序设计语言python、js等。
我平时用emacs,支持正则表达式。
在emacs里,把上述数据粘贴到buffer(相当于文件)中。执行命令 M-x occur,
给出正则表达式,得到类似如下结果,不完全符合我的要求。下面的结果,是我对当前文档执行的结果,匹配的部分是高亮的。

2. lazy
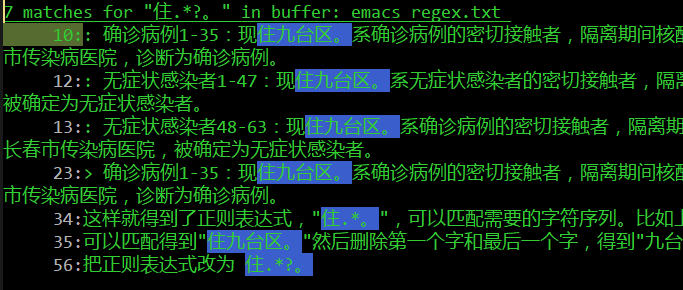
可以看到,匹配到的部分比我们预期的要长。不是在第一个遇到的句号 (。)停止,而是在最后一个句号,即尽可能长地匹配。
我隐约想起emacs正则表达式还有个 lazy 模式,查了一下,用?代表。
把正则表达式改为 住.*?。
好多了。

3. 仅保留匹配的部分
如果把匹配的结果复制出来呢。我只想要匹配的部分,不想要其余的文字,而现在的效果是给出了 包含匹配文字 的整行。
在网上查到一些emacs的lisp代码。还有一个简单的办法。
: As of Emacs 24, occur does in fact provide a simple solution:
: C-u M-s o .*pattern.* RET
其中的"C-u M-s o" 表示 ctrl-u alt-s 再按 o。
怎么这么稀奇古怪的。
我事先知道 C-u 是前缀,后面的才是命令本身。用 f1 ? k 查询,按 M-s o 查
到原来就是 occur 啊。
: M-s o runs the command occur, which is an interactive compiled Lisp
我一直喜欢命令序列,可以减少硬记的工作量。所以,我用 C-u M-x occur。
C-u 有什么用呢?
occur 的手册说:
: When NLINES is a string or when the function is called interactively
: with prefix argument without a number (`C-u' alone as prefix) the
: matching strings are collected into the `*Occur*' buffer by using
: NLINES as a replacement regexp.
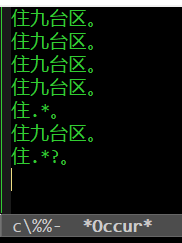
会把匹配的字符串 (而不是整行)收集到一个buffer (估且理解为文件) 里。
4. 去除首尾的字符
上述结果在一个只读的buffer中,复制出来,放到一个可写的buffer中。选中区
域,执行下面的指令。
: M-x replace-regexp
: ^.
:
: M-x replace-regexp
: .$得到以下结果。
: 九台区
: 九台区
: 九台区
: 九台区
: .*
: 九台区
: .*?
5. 去重
选中区域,执行下面的指令。
: M-x delete-duplicate-lines得到以下结果。
: 九台区
: .*
: .*?
除"九台区"以外的两行,是匹配到了上文中我写的正则表达式的。
6. 排序
选中区域,执行下面的指令。
: M-x sort-lines得到下面的结果。
.*
.*?
九台区
可以看到九台区被排到了正则表达式那两行的后面。
以上是在本文中运行的效果,真实数据的运行结果像下面这样。
: 九台区
: 公主岭市澜洋豪庭
: 公主岭市阳光首府
: 南关区十三局宿舍
: 南关区南城家园
: 南关区卫星商城
: 南关区星城国际大厦B座
: 双阳区太平镇桦木村9社
: 宽城区上台花园
: 德惠市中央公馆
: 德惠市国丰壹号院
: 德惠市幸福里岸
: 榆树市闵家镇东升村
: 汽开区东方之珠龙翔苑
: 经开区中海寰宇天下C区
: 经开区亚泰梧桐公馆
: 绿园区标记大厦
: 绿园区金色欧城
: 长春新区修正大厦
: 长春新区修正大学培训基地
: 长春新区北湾新城四期
: 长春新区恒盛豪庭

7. 后续工作
接着可以批量标注在地图中,看起来更方便。我没有使用方便,比如不需要身份认证的,没找到这样的工具。所以没再继续。
此外,emacs有个小工具 M-x re-builder,可以实时地在你修改正则表达式时,显示匹配的结果。适合正则表达式初学者探索。