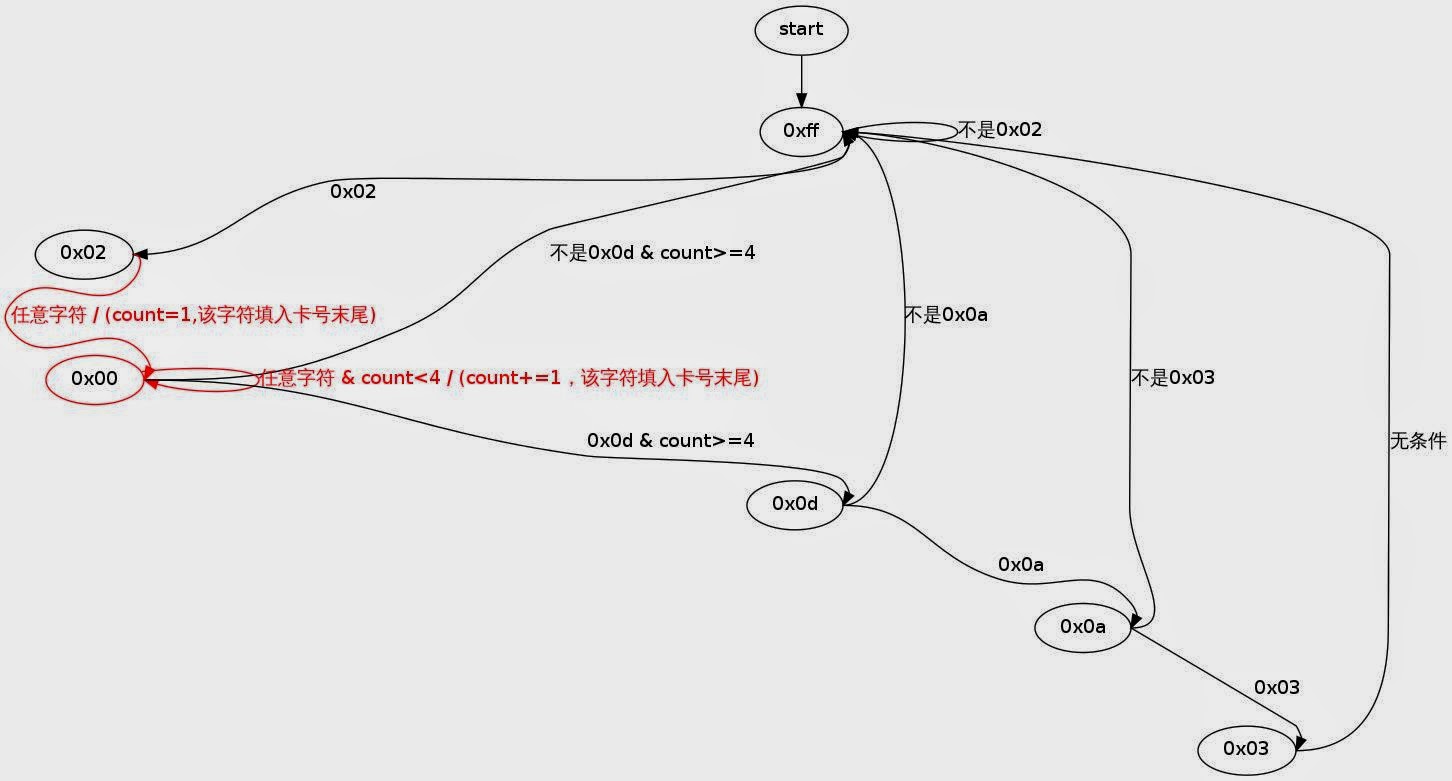
俄罗斯方块:win32api开发
本文简述一门课程,演示win32api开发俄罗斯方块的开发过程。假设学生学习过C
语言,没学过或者学习C++不好,刚刚开始学习 win32api程序设计,还不懂消息循
环和注册窗口类。
1. 背景和原则
我这学期讲一门课,本科三年级,学生满员17人。一般接近满员,最低一次5人,
那天据林同学说,其他的同学都去看足球赛了。
课程名字叫做算法与程序设计实践3。第一堂课我照例要解释:到了"3"这个阶段,
就不讲算法了,只有实践。不过,后来看看算法也还是有一点应 用,比如从一个
线性表里删除符合条件的元素们,在线性表里查找符合条件的元素,这种难度的。
课是在机房上的,大部分时间学生和教师都看着显示,所以一学期下来,好多同学
和我见面可能都不太认识。不过我们对代码的形成过程更熟悉一些。
我试图贯彻下述原则:学生应该看到教师编程的过程,而不仅仅是结果;学生应该
看到在编辑器和编译器中的代码,而不是WORD或PPT里的;学 生应该先学会临模教
师的编程过程,而没有能力直接临模结果;学生甚至应该看到教师的错误及错误的
解决过程、教师的无知及检索过程,学生不应该 看到事先排练的完美的编程过程
和全知全能的教师,那样的过程和专家,学生模仿时无从下手。
所以,我课前不准备,在课堂上无意犯各种错误--偶尔演示学生们容易犯的错误--
及解决。在LOG文件中记录我们的计划和当前的进度,在画图 里画下原型。
所以,我假装对某些API和函数不熟悉,演示在MSDN和互联网中查找手册和解决方
案的步骤。单独做一些技术原型验证对API的调用结果的猜 想,而不是在工程的过
程中在项目代码中测试技术。有时,我知道问题在哪里,但是要先列出各种可能,
然后一一验证猜想(而不是直接解决,这似乎 是计算机本科生非常容易犯的错误,
如果解决了就认定那是问题的原因)。除了这两点,其余的时间我应该尽可能诚实。
有时候,学生会告诉我哪里错了,先于我发现问题的原因。这令我享受这样的教学
过程。
最终,我们--以我编码为主--实现了WIN32API开发的俄罗斯方块。
选择俄罗斯方块的原因,是因为小游戏的业务逻辑足够复杂,保证学生了解在相对
复杂的业务逻辑时的面临的问题和编程行为与toy作品不同;所使 用的到技术较
少,避免过多的机制 (数据库、网络等)分散学生的注意力,保证学生把精力集中
在对业务逻辑上。
选择win32api是课堂上投票的结果。选择C语言而没有使用C++有两个原因。一是学
生的C++掌握通常并不熟练;二是我希望学生能在项 目中发现面向对象的必要性和
优点,而不是仅因为学习过哪些语言而在工程中选用;三是希望演示用C也可以实
现基于对象的程序设计 (不是面向对象,不包括继承,仅包括方法与数据的内聚)。
2. 技术原型
涉及到的技术原型,要在工程开始前建立小项目,以验证对这些技术的掌握和对效
果的猜想。
要实验的技术列表,来源于需求。我们先不写代码,口头描述需求,然后分解需求
到所需的技术。这样就形成了技术列表。这个过程中,同时也形成了 定义,包括
名词和动词表。
这些技术原型也限定了除C语言以外需要掌握的技术,在这次开发当中。
技术原型包括:
* 使用GDI画图、擦除。用于画小块和移动小块。移动是根据视觉暂留在新的位置
上画图,并把旧位置上的小块以底色重画。
* 键盘消息响应。用于在不暂停小块下落的情况下接受玩家通过按键操纵小块左
移、右移、旋转、快速下落。
* 特定范围的随机数生成。用于在创建新的小块时,决定是哪个类型。类型计有S
型、L型、凸形、田形,及它们的旋转。
* 计时器 (timer),用于驱动小块定时下落,判断是否该清除一行,计分,刷新工
作区 (重画) 等。
* 在工作区输出文字。用于调试和显示分数。
最终形成的原型部分代码量如下。代码在附件中的 prototype目录下
画图 (及消息循环) ,draw,226行
擦除,eraser,263行
在工作区输出文字,textout,201行
按键消息响应,key,207行
随机数,random, 31行
计时器,timer,214行
3. 开发过程的里程碑
技术原型确定以后,再重新回到需求,并把需求排期。争取每次课程限定完成一个
功能。
需求排期遵循的原则是:优先完成对其他功能无信赖的部分;优先完成核心功能。
以下是开发过程中的里程碑。
1) 生成块。
2) 计时器驱动,块自动下降
3) 键盘控制块 旋转、快速下降、左移、右移
4) 落到底或粘在底部已存在块上 (if (conficted || touch_bottom) stick)
5) 删除一行:删除一行,把之上的行下降一行
6) 计分:消除一行和多行分值不同
以下功能在本学期没有实现。
7) 生成新块前,在预览区显示下一个块
8) 分数积累到一定程度 (?),加快块下落的速度
开发过程以git版本控制方式记录了历史,每个重要功能一次commit,以日期作为
message。
4. 定义
我们在开发前用示意图约定了一些定义,作为词汇表。排版原因,我在这里有文字
解释一下。
俄罗斯方块元素:工作区上绘图的最小单位,是一个小方格。俄罗斯方块的名字
Terris 即四元素,因为每个当前块由4个元素组成。
数组元素:即C语言中的数组元素,数组中的某一个。提出这个定义是为了区别于
俄罗斯方块的元素。
当前块 (current block) :正在移动的由四个元素构成的块。有S型、L型、田字
型等类型。
已存在的块 (exist block) :堆积在工作区底部的,已经粘成一团的元素。
像素坐标,世界坐标。像素坐标是由GDI绘图定义的,世界坐标由我们定义,以元
素为单位,左上是原点 (0,0) ,向右向下递增。
stick。当前块接触到已存在的块,或者当前块接触到工作区底部,此时应该把当
前块加入到已存在的块中,然后生成新的当前块;如果导致已存 在的块中某一行
充满元素,需要按游戏规则删除此行,然后把已存在的块中此行以上的元素降落一行。
5. 数据结构及流程
以下介绍当前块、已存在块、键盘操作、删除已存在块中的一行的数据结构和流程。
5.1 当前块
当前块中,包括当前块的以下数据:当前坐标,上一次的坐标 (用以擦除) ,当前
类型 (接下来会解释),上一次的类型 (用于旋转)。结构体如下,整个程序中只有
这个结构体的唯一实例。
struct struct_block{
int x;
int y; /* row 0, col 0 */
int old_x;
int old_y;
int* type;
int* old_type;
};
当前块的类型使用数组实现,如下,分别是一字型、田字型、凸字型。
int line_v_block[]={0, 0, 0, 1, 0, 2, 0, 3};
int line_h_block[]={0,0,1,0,2,0,3,0};
int tian_block[]={0, 0, 0, 1, 1, 0, 1, 1};
int tu_v_block[]={0,1,1,0,1,1,2,1};
int tu_h_block[]={0,1,1,0,1,1,1,2};
数组中的每两个数值 (数据中的元素)代表一个当前块中的元素的坐标,计8个数值
代表4个元素。
生成块时,
current_block.type = line_v_block;
指定了当前块的元素。
绘图时,遍历"类型数组",把每个元素绘出。无论何种类型,都遵循这一流程,从
而实现"以数据作为代码":类型数组即数据,遍历"类型数 组"、在旋转时改变类
型等即为引擎。
旋转的代码示例,改变类型 (的指针) :
if(current_block.type == line_v_block)
{
current_block.type = line_h_block;
}
平移的代码示例,改变横坐标:
current_block.x -= 1;
自动下降的代码示例,改变上一次的纵坐标和当前纵坐标。
if(! is_conflicted() && ! is_touch_bottom())
{
current_block.old_y = current_block.y;
current_block.y = current_block.y + 1;
}
else
{
stick();
generate_block();
}
快速下降:
纵坐标 增加 所有元素中到达底部 (或已存在块中同一横坐标的顶) 的最短距离。
貌似题外话,helper函数:is_conflicted(),判断当前块是否接触到已存在
块;is_touch_bottom(),判断 当前块是否触底;匹配横坐标,给出当前块的底坐
标;求当前块距离底部的最短距离。等等。
开发helper函数的目的,是为了使程序整体流程清晰。保障整体清晰的方法之一,
是要求每个函数内容不得超过一屏。如果超过了,就需要折解 出 helper 函数。
在主流程中调用 helper 函数,而把helper函数体移出主流程,这样主流程代码长
度就下降了。这和小学写作文的时候,老师要求先拉大纲是一个道理。经常有同学
说,在开发过程中 会发现新的功能,在开发遇到新的技术,没有做原型的,因此
难以把握大纲。这都说明把握大纲和做计划的能力还差,需要通过练习来训练。这
和小学 生写着写着作文发现需要查字典,或者写跑题了,是一个道理。我们的成
长并非认识的字多了,而是能预见到将会用到哪些字 (甚至表达手法、写作素材)。
此外,在面向对象中,有些的函数会成为game (或者 current block 或者 exist
block )的成员函数。这在开发中会认识到,如果它们与数据能内聚在一个类中,
该是多么方便,因此了解面向对象的在信息隐藏方面的优势。这些函数应归属于哪
个类, 是由哪个类承担这个责任决定的。
5.2 已存在块
已存在块中包括以下数据结构:块的长度 (事实上,是块的长度*2,代码中以横坐
标和纵坐标作为两个数组元素) ,已存在块数组。如下。
int exist_block_size=0;
int exist_block[(maxx+1)*(maxy+1)];
这种数据结构,及当前块的数据结构,把横纵坐标无差别地,不以结构体地方式放
在数组中,在后续开发中带来了麻烦。不过由于课程时间有限,后 来,我未对此
做出修改。应该逐渐演化程序结构,形成以元素作为结构体的数组。再开发出一些
helper甚至成员函数,遍历时以俄罗斯方块元素 为单位,而不是当前代码中的以
数组元素为单位。
对已存在块数据结构操作的函数之一是 stick,用于在当前块触底 (或触及已存在
块)时,把当前块中的元素移到已存在块中。
有不少helper函数,基本都是通过遍历 exist_block,按匹配条件读其中的坐标。
包括:匹配横坐标,给出已存在块的顶坐标 int get_exist_block_top(int x)。
5.3 键盘操作 & 动作序列
玩家操作块这一操作,由键盘消息响应开始。我们不在键盘响应中处理这一事件,
而是只在这里记住这个动作,加入动作序列中。这是后来的版本。最 初的版本,
我们也不在键盘响应中处理事件,而是调用 block.cpp 中的函数。原则是:凡依
赖win32api的,放在 tetris.cpp 中,如 timer, 键盘响应,绘图;凡是与业务逻
辑有关,平台无关的,放在 block.cpp 中。接收向上箭头,是键盘响应,平台相
关,所以放在 tetris.cpp 中;此时调用的 rotate,用于改变当前块的类型或坐
标,平台无关,所以放在 block.cpp 中。
动作序列的数据结构如下。在动作序列数组buffer_action_seq中,数组动作元素
(动作) 的类型是 枚举 action。
enum action{ action_left=1, action_right=2, action_speed_down=3,
action_rotate=4, action_down_auto=5, action_na=0};
action buffer_action_seq[action_size]={action_na};
int buffer_action_cursor = 0;
由玩家触发键盘消息开始,流程如下。
1)键盘消息响应:
buffer_action_seq[buffer_action_cursor++] = action_rotate;在动作序列中加
入一个动作。这对应于设计模式中的 commander 模式要解决的问题。
2)在timer中自动下降
timer中 buffer_action_seq[buffer_action_cursor++] = action_down_auto; 在
动作序列中加入一个动作。
3)在timer中触发WM_PAINT
timer 中 InvalidateRect 触发 WM_PAINT
4)WM_PAINT中执行动作序列
erase_old_block_seq(hdc);
erase_old_block_seq (hdc) 遍历动作序列,按每个动作改变当前块坐标,然后擦
除由于动作产生的旧块。遍历动作序列以后,就完成了自上个 timer 周期以来所
有的动作,擦除了这期间产生的所有旧块。
void erase_old_block_seq(HDC hdc) 片断如下:
for (i = 0; i < buffer_action_cursor; i++)
{
switch (buffer_action_seq[i])
{
case action_left:
move_left();
erase_old_block(hdc);
break;
在序列里的每个动作中,move_left 改坐标, erase_old_block(hdc) 擦除旧块.
5)WM_PAINT画新的当前块和已存在块
draw_current_block(hdc);
draw_exist_block(hdc);
因为重绘比计算花费的时间要多,作为性能优化,如果当前块与旧块坐标完全相
同,不重画。
另,另一个版本的动作序列,不使用枚举和swtich-case,通过把函数作为消息传
递给责任者,实现disptach:
void (*next_action)() = move_still;
next_action = move_left
其中 move_left是一个函数。next_action这样的元素 (类型是函数) 组成一个数
组,作为动作序列。执行动作序列时,用下面这样的代码:
while ( next_action++ != action_termination )
next_action;
由于 next_action 既是函数,也是数组元素的指针,因此上述代码不是伪代码,
而是可以执行的。这类似于 jump table 技术,数组元素的类型函数,可以遍历数
组,执行元素对应的函数。
5.4 删除一行 & 计分数
每个 timer 中,都调用 void kill_all_full_lines()。它遍历 exist block,凡
符合满行条件的,调用 kill_block_in_line 删除该行,调用
move_exist_block_down_line 把该行以上的 exist_block 下降一行。
这三个 helper 函数都是通过遍历 exist block 中的每个元素,匹配坐标条件,
然后删除数组元素或者改变数组元素的值。如前所述,由于 exist block 封装中
未使用 俄罗斯方块元素,所以这些遍历都写得非常丑陋。
删除一行以后,累积删除的行数。全删以后,根据删除的行数进行 switch-case,
向全局变量 score 累加分数。在下个timer中,把 score 用 textout 输出到工作区。
6. 回顾和检讨
6.1 数据结构,封装,循环条件
由于最初的 (也是最终的)数据结构设计偷了懒,后来又没有足够的时间修改,此
前已经提及两次,exist block的结构过于贴近平台,而远离需求。exist block的
颗粒度太低,是以 int 为类型的 数组元素,对应于需求中的 俄罗斯方块元素 中
的横纵坐标之一。某个数组元素到底是横坐标还是纵坐标,到底是第几个俄罗斯方
块元素,这些都需要由代码实现。这样,按需求写helper函数的时候,遍 历的元
素选取、终止条件,都遇到了麻烦。我在课堂上写作时需要考虑,有时还会错。经
验说明,当我需要仔细考虑,或者讲述时间较长时,学生听懂 可能已经有相当难
度了。终止条件错误的bug,在代码中存在两三处,导致在 exist block够多时,
即游戏进行一段时间,工作区中会出现莫名其妙的俄罗斯方块元素。这个bug在最
后阶段才解决。
这个故事告诉我们,设计不好,对编码实现的难度要求就会提高。战略失误,战役
和战斗就不容易打。领导决策肤浅,要求下属跑死,结果也是白扯。 道理都是一
样的。
6.2 不要对付过去
在开发中间的某堂课,我们发现当前块移动时后面留了尾迹,擦得不干净。这些那
堂课快结束了。为了能让学生在课后重复我课堂上的工作,所以我" 对付"了代
码,由局部刷新改为刷新整个工作区,包括背景。这样尾迹表面上清除掉了。
之后,延续了这段"对付"的代码。直到期末将至,我才发现这段"对付"掩盖了另一
些bug,坐标移动的bug导致除非刷新整个工作区就有尾 迹。这个bug在最后阶段才
解决。
6.3 并行,timer
有文章指出,初学者非常不容易理解的程序概念包括:赋值、递归和迭代、并行。
本程序中有几个埋得比较深的bug,是由于我对并行没有足够警惕 造成的。
timer, 键盘响应,WM_PAINT会并行发生。当其中一个未处理完的时候,另一个可
能就开始执行;甚至timer未处理完的时候,另一个timer也可能会开 始。而这些
并行的代码,都调用了 block.cpp。比如有时导致其中一个正改坐标尚未完成,另
一个开始刷新工作区,这样工作区里就出现个元素,位置是乱七八糟的。
并行的处理,需要 原子操作、进程间通信、避免重入 等概念。上述提到的动作序
列,目的之一就是希望擦除旧的当前块这一动作只在 timer 中发生。
在本课程中,应该不期待学生具备这些操作系统中的知识。不过我还没有想到该如
何设计才能规避这些知识。不过我猜应该类似于不用线程也能设计出 贪吃蛇,应
该有依赖更浅显知识的设计手段,比如单纯轮询,而不用事件响应、消息循环。有
哪位知道,请赐教,谢谢。
6.4 猜想后,应该先验证,然后再修改
学生们通常把验证猜想和实施解决归约成了一步,我也经常如此。下文中的他们,
包括我。
他们观察到问题,然后做出猜想。这是正常步骤。
但是他们不以实验验证猜想是正确的,急急按猜想修改代码。如果问题消失了,
好,他们假设抓住了问题的原因;如果问题还在,就再做个猜想,然后 又马上修
改。甚至更糟糕,没有退回到上一步的起点,就在当前工作代码上"继续"修改,让
各个猜想累加起来,最终问题解决的时候甚至不知道是什 么原因。
应该先设计实验,按猜想的模型,如果怎样就会怎样。验证猜想以后,再去解决。
比如假设由于 timer 和 keyboard事件响应 同步导致画图混乱,那么,不应该着
争写进程通信,而是 应该先选用简单粗暴的手段 去除同步,以更大的颗粒度作为
原子操作,验证猜想。如果猜想正确,现象应该有所改变。虽然影响性能和效果,
但这并不是准备最终采用的代码,只是用来验证猜 想的。当猜想验证以后,再去
想效果更好的方案真正解决,比如建立个变量作为信号灯。
6.5 不要轻易更换技术方案,试图绕过问题
这个方面,我最初是发现计算机本科的同学倾向强烈。经常有方案,明明再向前一
步就能解决,他们却在此时换了方案。问为什么。答:因为这个技术 解决不了这
个问题。
确定"不"是极其困难的,甚至比确定"能"要难上很多。你不能,并非就能确定这个
方案不能。
需要充分了解你所使用的技术,对它能够完成的任务有足够和明确的自信。同时,
对用来替换的方案能解决何种问题,也应该明确。做原型验证,根据 理论推论,
这些都是解决之道。见到工具,拿来就用,偏听偏信别人的评论,就太草率了;一
旦发现并非万能良药,转身就去寻找就的手段,这就更草 率了。
6.6 版本控制
为了让学生能看到开发的过程,我上课时用文件系统做了版本控制,每次课一个目
录,有时压缩成zip。课程结束以后,一个版本一个版本加入 git,然后commit,
操作了两个小时(?),其间又担心整错了,苦不堪言。
下次一定要从最开始就做版本控制。还要在 commit 前把 debug, pch, sdf 等二
进制垃圾手动删除。
7. 附件
附件是以git版本控制的代码及日志,在这里[http://download.csdn.net/detail
/younggift /7499881]。
protype下是技术原型。
tetris下的是俄罗斯方块项目本身。早先的版本是VS2010的,最后一天的是VS2012
的。你可以仅代码部分添加进win32工程, 以适应你的VS版本,或者dev c++版本。
log0.txt是课堂上的日志。log1.txt是最后一天前期的日志。log2.doc是最后一天
后期的日志,因为需要截图,所以改成用 word。
pic.bmp是图片,用来说明定义的。
branch是一个分支,我忘了它是否加入了 trunk,留在那里备用,以防遗漏。
--------------------
博客会手工同步到以下地址:
[http://giftdotyoung.blogspot.com]
[http://blog.csdn.net/younggift]