用AHK (AutoHotkey) 写了个脚本,在PC/Windows操作系统中调用微信客户端,定时@ 特定人员 单发/群发 (?) 消息。
1. 问题及此前的工作
本轮疫情以来,我所在单位的不止一个有关部门发出了不止一次不止一个要求。其中一个要求,是要求导师每天向每名研究生询问情绪是否稳定。如何上报,等以后通知。不过,在如何上报出来以前,就应该有行动,不然一旦要求上报,报啥呢。我怕除了聊天和学术上技术上的讨论以外,万一忘了每件特别是这件重要的底线,又根据 DRY (Don't Repeat Yourself) 原则,所以考虑应该自动化。
当然,我们就如何实现进行了反复实验和深入的讨论,成功地把这个重要而 的任务变成了有趣的技术问题。不仅执行要求,也分析要求,按 正念 的观点,觉知正在进行的任务以及感受,有效避免了抑郁。
田同学用 appium + 真手机 做了一个版本,在这里[https://www.cnblogs.com/ourshiningdays/p/16023291.html]。非常成功,到每晚1024这个时刻,就由 appium 通过USB线调用手机上的微信,把消息发出来。
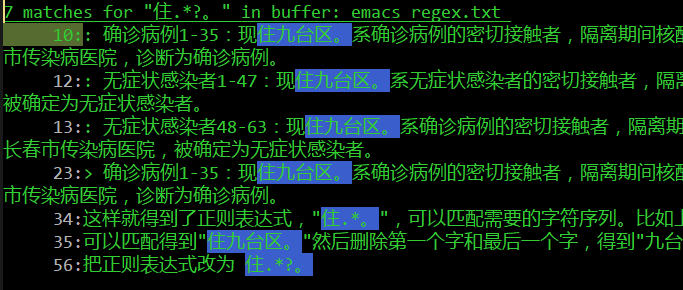
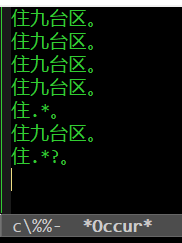
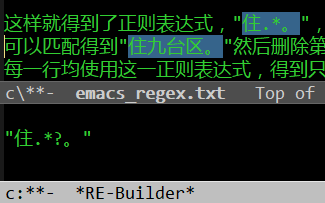
他发现,"@杨贵福"这种写法不行。"@杨贵福"并不是一段文字,我用实验复现了他的发现,确实如此。"@杨贵福"能复制,但是不能粘贴到记事本中。根据DDE应该能进一步确认复制出来的到底是什么以及格式,不过,知道不行也就够了。田同学发现必须先"@",等微信列出名单,再输入名字匹配才行,单纯输入"@杨贵福"或粘贴这段文字,不能起到@的"呼叫"效果。
田同学还做了加强版,等10分钟,然后解析同学们 (和我) 的回复,确认大家都表示了"稳定"而且不是"不稳定"。凡是没有回应或不稳定的,@导师提醒,并给出名单。
完美。我问,你咋不用夜神一类的仿真器呢,是因为微信在仿真器里登录以后,会踢手机上的微信下线,而你没有另一个微信号么?他说,他有另一个微信号,也在仿真器上试了。被微信侦测出使用仿真器,已经封号两次了,再封的话号就没了。
于是,有了我今天介绍的这个版本。

2. 技术路线
AHK是个脚本工具,语法有点像VB。本轮安装以前,我没有想到,这东西如此友好,甚至不必安装,解压就行。因此可以认定干净并且不烦人。烦人,指安装全家大礼包、修改开机自动运行和服务、特别大个,等等。AHK这点不错,解压完以后9M。
AHK可以模仿键盘和鼠标的动作,可以窗口和屏幕上的控件,可以读颜色。这么说吧,你能干的事,它都能干。因此,也可以作为GUI的测试工具,而不仅是个自动化工具。
因为在微信上回消息,用手机实在太慢了。回消息的时候除非手头没有PC,我不用手机。所以我的PC微信客户端本来也经常长时间登录在我的座机上,虽然经常隐藏在我当前工作桌面以外的另一个桌面中。随时唤起,也可以被AHK唤起。
思路大致如下,用AHK模仿人手的动作。我先把下面的步骤想清楚,写在代码里,加上注释,算作大纲。然后开始从上向下写代码。
第一步,找到微信窗口
用ahk的小工具WindowSpy找到微信窗口,可以根据窗口的标题、进程名 (程序名)或进程号、win class之类的区分。我用 ahk_class。
: WinActivate, ahk_class WeChatMainWndForPC
实测时发现,如果微信窗口被ESC消隐,就不能 WinActivate 切换到前台。所以在此之前尝试运行一下。
: Run, C:\Program Files (x86)\Tencent\WeChat\WeChat.exe
然后sleep 500毫秒,等待万一微信需要启动。后面还要经常sleep,即使我们肉眼以为瞬间完成的,也需要等一下。下略。瞬间这种事,在计算机中不等价于同时。

第二步,找群
找群这个动作,微信支持用快捷键 ctrl+f,然后输入群名,回车。
所以用AHK模仿键盘,不操作鼠标。
: Send ^f
: Send %group_name%
: Sleep 1000
: Send {Enter}
group_name是个变量。考虑到别人用这段代码时群名可能变化,所以在脚本最开头,定义群名。

第三步,清空原有消息
此时已进入群聊的窗口中,光标在输入文本框中。考虑到一个场景,在此之前脚本的使用者可能正在使用微信,也许正在此群中,并且已经输入一些文字。但是这个场景并非MVP (Minimum Viable Product),所以推迟到以后的版本 (如果还有的话)再实现。
在这里,为避免原有文字干扰发送的问候,仅做简单粗暴处理——全选,清空。
: Send ^a
: Send {Del}

第四步,循环,应@尽@
这一步构造要发送的消息,@每一位需要@的同学。一方面因为群里有已毕业的同学,不宜打扰。另一方面,"大家没事注意点儿群里的消息"或者"@所有人"都很烦人。
在脚本最前面把每一位需要@的同学的 群昵称 放到数组中作为一个元素,在此处遍历数组。
对于数组中的每个元素,先发送 @,sleep,然后发送群昵称一个,sleep,发送回车。这样就@完一位。每轮循环的最后根据是否最后一位同学决定发送句号还是逗号。
遍历数组以后,发送问候的消息。我还顺便附带了当前时间。
再发送个回车,把这条消息发送出去。

第五步,定时
这是最后考虑的,但是不是在最后执行的。
定时可以像田同学那样,使用windows定时任务,或者用 linux cron这一类的机制。也可以按当年李记者告诉我的更常用的手法,轮询,跑死循环,在每次循环里检查是否要运行的时刻,然后sleep节省CPU。
也可以像我这次这样,抄了一段代码。从这里抄的,[https://blog.csdn.net/liuyukuan/article/details/53860122]。
在程序运行之初算一下还差多少秒到要运行的时刻,sleep这么长时间。
: StringLeft,当前日期,A_Now,8
: 提醒的时刻 = %当前日期%%定时%
: 提醒的时刻 -= %A_Now%, Seconds
: Sleep 提醒的时刻*1000
这就行了。在预定的时间每晚1024,应@尽@,发送问候。

3. 实验结果及改进
白天试了两下,通知同学们不必理我。大家看完消息以后,讨论了一会儿,表达过和表达了对一些问题的担心/估算。比如要sleep,要sleep多久。万一同学也用脚本回复怎么办。也许应该讨论的"怎么办"不是如何应对,而是如何达成?、
当天晚上,AHK脚本如约运行。第一位同学的名字前面没有@。这位同学指出我一定是没有sleep。正是,改。
改的过程中发现,要测试好几次。要避免定时sleep,而希望马上执行看效果;要避免消息构造完成以后不慎回车把消息发出去。所以,我定义了 测试模式。
: test_mode = false ; true
: ...
: if (test_mode != "true"){
: Sleep 提醒的时刻*1000
: }
: ...
: if (test_mode != "true"){
: Send {Enter}
: }
4. 展望
工作总是可以更美,不过留到以后吧。当前版本就可以对付用了,就这样发布吧。
以后要工作:
(1) 发出消息后10分钟后查回应,如果没回复需要提醒
我们讨论到的方案是截屏(可能需要滚几屏),OCR,然后解析。
(2) 保存现场和恢复:发送消息前,由系统暂存未发出的消息,群发消息以后再粘回来
5. 附录 代码
; 要在以后的版本中再增加的功能
/*
1. 发出消息后10分钟后查回应,如果没回复需要提醒
2. 保存现场和恢复:发送消息前,由系统暂存未发出的消息,群发消息以后再粘回来
*/#SingleInstance force
; 测试模式
test_mode = false ; true; 微信群名
group_name = 软件所-现役; 人名清单
;message_receiver := Object()
message_receiver := ["位军营", "杨萍", "张宵", "2020-史志腾", "杜蕾", "韩亚光", "田洪轩", "唐一钦", "李娜", "马洪博", "王涛"]; 问侯语
question = 来来来,请回复一下,今天你情绪还稳定么?我还对付。; 在规定时间 10:24 启动
; 代码参考 [https://blog.csdn.net/liuyukuan/article/details/53860122]
; 群发消息的时刻, 22:24:00,格式222400
定时= 222400;--------------------------------
;---------------------------------
; 通用AHK脚本启动
time_out = 5
msgbox , , 信息 , 运行中,%time_out%秒钟后AHK脚本开始倒计时, %time_out%StringLeft,当前日期,A_Now,8
提醒的时刻 = %当前日期%%定时%
提醒的时刻 -= %A_Now%, Seconds
if (test_mode != "true"){
Sleep 提醒的时刻*1000
};--------------------------
; 通知用户不要手动操作计算机
time_out = 5
msgbox , , 警告 , 请暂停手动作操作,%time_out%秒钟后AHK脚本将通过微信群发消息。`n如有必要立即保存当前消息。 , %time_out%; 找微信窗口
Run, C:\Program Files (x86)\Tencent\WeChat\WeChat.exe
Sleep 500
WinActivate, ahk_class WeChatMainWndForPC; 找群
Send ^f
Send %group_name%
Sleep 1000
Send {Enter}; 清空原有消息
Sleep 1000
Send ^a
Send {Del}; 循环
; 在群中@每一位用户
; 发消息
;Send {当前时刻%A_Now%,}for index, element in message_receiver
{
Send {@}
Sleep 500
Send %element%
Sleep 500
Send {Enter}
if (index < message_receiver.Count() ) {
Send {、}
}
else {
Send {,}
}
}
Send %question%
Send {^Enter}
Send %A_Now%
if (test_mode != "true"){
Send {Enter}
}; 下一版本再实现
; 10分钟后查回应
; 找群
; 选文字?读ExitApp
return