




 .
.
Author: 杨 贵福
ACM-ICPC全国邀请赛,长春
ACM-ICPC全国邀请赛,长春今天早晨做梦,还在对周老师说:"你们先整,到关键的时候叫我啊。"也许是老
了,以前似乎没有过这么深刻的印象,以致于结束以后还要念念不忘。因为在比赛前腰间盘突出,弯腰很困难,在整个比赛期间,就是坐着或站着看大
家工作。站着够键盘都吃力,真正能伸手的工作,就非常有限了。时不时还要找
个平的地方躺一会,整个是半残障人士。所以,经常是周老师叫我,"你得来了
",然后,我才出现。周老师身兼N职,累得在热身赛的时候在现场睡着了。李老师一直值守在服务器旁
边,她离开服务器的时间总计不到10分钟,且表现出10余年unix管理员的优秀素
质。网络中心的娘家同事们送来了12台交换机和1台千兆交换机,及无线键鼠一套,还
架设了三个无线AP,图书馆娘家的同事送来U口键盘2套。ACM比赛是个大事件。不少计算机学院的同学看到了自己与别的院校的差距,还
有人体验到了生活,累得很快乐。一定还会有老师站出来说,大家辛苦啦,干得
都不错。我只是个技术人员,只看到技术。非技术类的同事和同学们的辛苦,亲眼所见,
但并无亲身体会,就不在这里矫情说什么辛苦了我爱大家之类话了。且我不是负
责人,只能代表自己,不能代表领导和广大人民群众。以下,技术方面的小结和乱谈。1. 系统边界当完成别人交给我们工作的时候,有两种境界:一是精确完成,二是有创意的完
成。请注意,有创意的完成,是以精确完成为基础的。也就是说,创意必须在精确之
上。非精确而有创意,这并非是一种境界,而是一种极其不靠谱的混蛋做法。你要么不要答应这份工作,要么就完成它。如果不能完成,尽可能提前通知。而很多人的做法正相反:或者临期不完成,且没有事前通知;或者完成得半正确
不正确,只有重做才能用--或者说完全不能用。比如下面这段对话就比较典型。我:要求你完成的XX功能,我以为你已经做完了,没有想到你需要现场调试。没
做这个计划。程:一会就能调完我:问题是明天就得安排把装机器的屋子开着。评论:我确实见到过不少人,说好地联调,但是到了现场才发现他什么也没做,
准备一边做一边联调。这种完全不把别人的时间当成人类时间的做法令人愤怒。
有个别领导召唤我去以后,才开始找要给我的材料,然后找不到或者找很久,我
说过:"你慢慢找吧,我先走了。"我们约见是要讨论只有约见才能讨论的东西,
你自己可以独自完成的,请独自完成。我一点也不想陪你消耗生命。对话继续。我:好了,明天屋子会开着,你调吧。这时有同学告诉我,程从二楼下来了。此前我们的电话的原因是他在二楼,我在
一楼。我说,我还没让他下来啊。这涉及到下面的另一个问题,有始有终,稍候
再说。我:你等会再下来,把机器关了,把主机和显示器的电源线都拔了。程:好。等程同学出现在我面前,我问:电源线你拔了么?程:没有啊。我把插排开关关了。我恨不得踹他一脚。有同学事后说,你肯定是没说清楚。我记得我的原话,拨电源线,不是只断电。我:我让你拔电源线啊,那开关要是坏的呢?程:插排开关是好的啊。我:如果着火了呢程同学跑去纠正了。如果着火了,2个亿的体育场就毁我们手里了。有的同学说,唉啊,不能啊,有
防火,有ABCD,有甲乙丙丁保证。如果什么都要别人保证,你的贡献在哪里。要别人的保证的,就是孩子,是需要
别人照顾因此不能以成年人的身份受到尊敬。事实上,我不得不强调,程同学是我所见过的非常优秀和聪明的同学。他的工作
极有效率,程序甚至美工卓越。举他为例,真正的原因是他的例子还值得一举。
有位同学在负责老师说"明早班车是7点,别迟到了"的时候,说"不能7点10分么"。我非常震惊。不仅对"7点10分"这一要求,也对负责老师会提到"别迟到了"感到震
惊。这是多么简单的现代汉语,7点的意思就是7点,不会包含7点10分的。留作业
的时候我要说,"最迟21日的意思是21日晚24点之前",我觉得自己很弱智,对听
我讲这话的同学的智力也是一种侮辱。但是,我们又乐此不疲,你认为原因是什
么?在你有各种创意和扯淡逗乐之前,能够精确地完成你所承诺的事情,极其重要。
重要到,有时候别人更不负责任,也不必指责。像我现在所做的,就是弱智的没
必要的事。我们就在比赛前推迟开赛1小时,因为40台左右选手用机不能引导。那是因为前
一天准备机器的时候没有进行最后一次引导检查。不过,这并不影响上面的讨
论,因为我不想说我多么认真,而是仅指出不认真是多么得令人不能忍受--我自
己的不认真也是一样。系统边界是我们对于外界的承诺,即我们可以承担何种责任。这是我们在一个更
大的系统中存在的原因。既要精确完成自己承诺的,同时,也不应该超过自己承诺的范围。比如下面这件事。热身赛前一天,我们在测试计算机接大屏幕的时候,所有人都没有找到是谁负责
大屏幕。我,周,封,刘鹏同学在玻璃房子里面束手无策,已知体育馆的管理员
不知道该找谁。此时我犯了一个错误,即开始自己解决如何连接这一问题。事后张老师指出,"
你应该找我,我负责协调。"我错了。避免麻烦应该像李辉老师那样,跑到外面
借交换机,但是不能越过边界。我把大屏幕接上了,人家负责接线的人找上门来兴师问罪了。这是我的错误。类
似的,我对程同学说过,"你能不能不评价我们的工作","你最好别表现得好像
周老师的领导似的"。类似的,我对张同学专家说过,"你有解开U口的能力,但
是你没有解开U口的权限。"类似的,我也评价过李超同学专家,他的成熟和技术远超过我们的同学。其中非
常突出的一个表现就是,他每一次都是建议,而不是"你们应该如何"。周老师说,按我以前的做法,我会开除一些志愿者。其实,我一直以为那是和善
的作法--因为我及每一个人都没有权利指导别人该如何为人,我们所能做的只是
消除可能的隐患--尊重开除的志愿者选择的权利。工程中,大系统如同齿轮,每个超出或低于设计要求的,都可能破坏整个系统,
应该剔除。2. 有始有终现场,我看到三个人躺着过,其中一个人是我,腰间盘突出不能久坐的。同事们
提到过志愿者同学有躺倒的,有坐一边发呆的。是体力么?大家的体力确实不怎么好。大连ACM赛的时候爬小山包,几位选手累得够呛,比
我们这些老一些的家伙体力更有不如。但是我并不相信这是体力的问题。而是--对付。对于不喜欢的工作,要断然放弃,不要勉强,无论里面有多么大的好处吸引你。
放弃它也饿不死你的。即便是好处当前,有些同学还是会放挺的。我在他们的身上看到了孩子气--拒绝
成年,拒绝承担责任。可能青春期现在延长到30岁了吧。人类将成为很早进入青
春期很晚退出青春期的动物。你是否读过 威尔斯 的 时间机器。阳光下那些白白净净的家伙,晚上都是要被
吃掉的。它们就是永不长大的幼儿。中间放挺的有之,还有任务结束不回馈的--大多数。如果任务结束不回馈消息,
发出任务的人就得轮询,而不能采用中断机制。也许,不及时回馈坐那等的一个
动机,正是希望休息,也许只是发呆没有主动性而已。所以,我不得要不要求跟我较熟悉的研究生同学。你们要一直跟着周老师,看他
做啥就接过来做;你们做完什么事情要及时报告,好分配下一件工作。也许大环境使然吧,因为领导通常也不在结束的时候通知"你们可以解散了。"就
像我们贴上禁止啥啥,很少在取消的时候贴上取消禁止,那么胆大的就尝试吧。
契约和法的精神于是全宣告失效,虽然小资产阶级们成天叫嚷这两个时尚的词儿。3. 人,生而平等说好第二天戴工作人员牌可以进出,我到体育馆的时候,被门卫告之,"得等你
们领导老师来了一起进。"我事后问过协调的张老师,"请你沟通一下,一起是什么意思,全到齐么,缺一
个也不能进么。"后来知道,协调的张老师通知了体育馆的领导,但是体育馆的领导没有传达消息
给门卫。所以,有同事说,"门卫只是不知道变通而已。"我反对。"如果他们不知道变通,为什么没戴牌的付老师和封老师就放进去了。"我当时的决定是,明天,我要戴牌直接进,不会等"聚齐了",如果不让进我转身
就走。第二天,有志愿者值班,顺利通过。不放我及我们进的原因是:我们像学生。同学们都知道我不是学生,一起打趣我,你不就是老师么。我不是,我与同学共
进退,我甚至不愿意称呼学生为"学生 (第二个字轻声)",因为这个字眼在北方方
言里已经具有了歧视的意味。(我坚信不出10年,大多数同学都会开始俯视当年的
这些老师了。)人,生而平等。因此必须享有相同的尊重的权利,而且不是故作姿态的假惺惺的。我所说的平等,并不包括:老师订盒饭,同学去食堂,当然也不包括我吃麦当劳。
我吃麦当劳是我自己付钱。老师订盒饭类似于另一件事。几年前计算机学院四楼有个打水的屋子,里面有纯净水,很多同学去打,领导和
老师们都说"唉呀,喝就喝呗。"我一直觉得同学去打水是错误的,跟关 (刘?)同
学提到过,她说,"就喝点水么。"问题是,水是花钱买的,即使只有一分钱,那
也不是你的。所以,平等并不包括这些。平等仅包括把你视为成年人 (其实很滑稽,你的确是
成年人,这事实如此清晰),作为成年人尊重和放弃。有同学说,我们不是还在成长阶段么。也许吧。不过以下两种待遇你只能选择其一而不可兼得,要么作为成年人,要么
作为青少年。你不能享受成年人的待遇,行事却是青少年。这多么像有些人一边
呼吁女权和男女平等,一边呼唤农耕封建社会的制度。我为争取平等的尊重付出了代价。2004年,我对领导说,"你对门卫出示证件么。
"领导说,"他认识我。"我说,"他还认识我呢。"没有平等,就没有合作,于是,我
被辞职了。类似的,如果你希望作为成年人被尊重,请做事像个成年人。4. 脚本我一共写了两个shell脚本,都非常短。一个用于备份服务器的答题记录,另一个用于
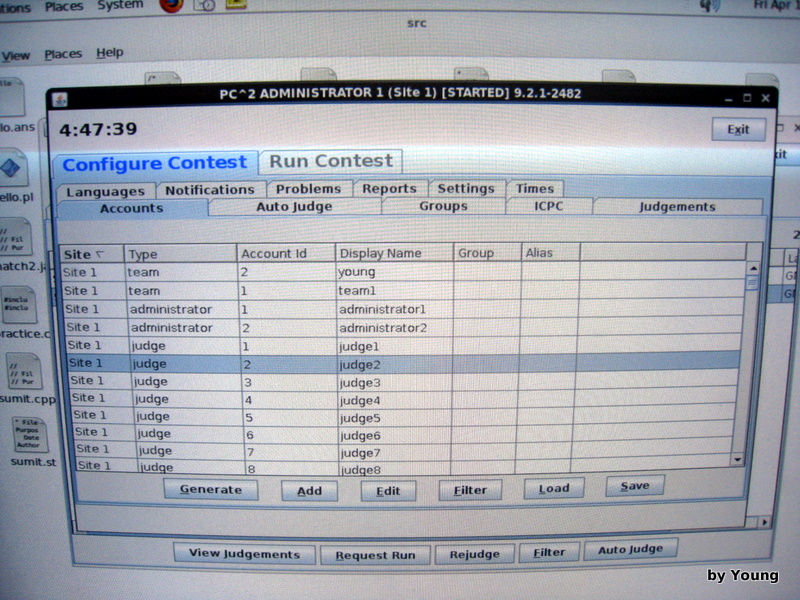
传出答题排名 (board)。之所以使用shell脚本,而没有采取任何看起来更高端的工具,是因为shell脚本
足够短而可靠,同时,只要是Unix系统管理员都能够维护。备份的脚本,每5分钟把pc^2 (比赛用系统)压缩并备份一次,打时间戳作为区别。
计划是如果服务器完蛋了,立即在另一台备用服务器上解压缩然后继续比赛。脚本如下。#!/bin/bash
while [ 1 ]
do
DATE=`date +%C%y%m%d.%H%M%S`
echo "------------------------" | tee -a backup.log
echo $DATE |tee -a backup.log
tar cvfz pc2.back.$DATE.tar.gz pc2-9.2.1 1>> backup.log 2>> backup.log
echo "done"
sleep 300
done讨论过的几个问题如下。* CPU负荷:压缩需要消耗CPU,这是否会导致服务器过于繁忙?不会。因为压缩每5分钟一次,到最后pc^2积累的数据最多的时候,最慢也会在10秒左右
结束。同时,因为评判时程序的运行是在裁判机上,服务器的CPU大部分时间闲
置,只有在大量提交的时候,可能由于网卡不够好,网络通信占用了一些CPU时间。
与热身赛时偶像给的压力测试题在自动评判情总下的海量提交所造成的CPU冲击相
比,tar的那点时间根本不算什么。这样,在服务器崩溃时,我们可以回退到至多5分钟前的数据。有同学提出,我们是否可以在服务器崩溃的时候热切换到备份服务器,让赛场内
的选手不觉察。这样,当时用户的体验可能不错,不过长久看来,受骗的感觉并
不好。所以,我们事先计划,只要服务器崩溃,即使选手不通觉察,我们也一定
会暂停比赛,广播通知。* 为什么不在同一台服务器上继续比赛因为服务器崩溃的原因至今不明。大家都猜测是pc^2使jvm堆分配时out of
memory,但是目前都没有日志作为证据,甚至没有一个亲眼见到证据的人站出来
发言。所以,不能完全断定服务器崩溃的原因,保守的方法就是换一台服务器。* 为什么不用cron/at而使用sleep为了其他人维护更加方便。尽可能不假设别人拥有相同的技能,是厚道的做法。
如果使用cron,当别人问到怎么用的时候,说"看手册"去,确实很酷,但并非合
作的态度。而sleep就在shell之中,可以认为是自文档的。让别人满机器猜测寻
找你放的东西,这种感觉掉过来感受一下就知道是什么滋味。有名言曰:程序员最痛恨的两件事,一是写文档,二是读没有文档的代码。别人也是人类,因此应该把别人当作人类看待。* 为什么不备份到别的地方去,比如U盘或者网络我亲眼见到在服务器上插U盘导致windows服务器蓝屏死掉,当时正在进行百人左
右的考试。因此,在正运行的服务器上插点什么东西,是不安全的。不备份到网络考虑两个原因:一是会占用带宽;二是麻烦。确实可以使用rsync
之类的工具,但是反正服务器死掉是要广播通知的,恢复比赛所需要的时间是5
分钟还是1分钟,没有多大差别。另一个脚本是上传成绩,分两部分。第一部分,lftp脚本:open 192.168.1.230
user upload 口令
cd ~
repeat 60 mput *html
bye第二部分,调用上述lftp脚本的shell脚本。#/bin/bash
lftp -f upload.lftp之所以要有第二个脚本的存在,同样是为了别人用起来方便。在别人不知道怎么
用的时候洋洋自得地说,"这不就是lftp脚本么,这么用"非常不厚道。之所以用ftp是因为它用起来简单。之所以不用程同学的非常优秀的代码从服务器拉数据,而是坚持推送,是因为我
不信任他。保证服务器工作正常是我最主要的工作,这一工作及责任,我不应该
移交给他人。我担心程同学没有按他承诺的频率拉数据,我担心pc^2 api有bug会导致服务器
崩溃,我担心程同学在我要求封板的时候依然拉数据。等等。而推送数据能避免
所有上述问题。提到信任,建一说过:人不信人枉为人。我想了好几天才答复:我们不能把自己
的责任交给他们,仅以信任约束。信任别人包括两个方面,信任他不会骗你,和信任他有能力不骗你。后者,就是
移交和推卸责任。所以,虽然程同学的代码很优雅,我也仍然坚持这个笨办法。5. 小结对不认真的同学,及自己,我总是想起甲午海战。甲午海战的时候,中国和日本都拥有当时几乎同等先进的舰船。但是,据说我们
的士兵甚至在炮筒上晾晒衣服。甲午海战,中国大败,这次失败的影响一直持续
九一八到1937到今天。当我们对这些理当亡国的混蛋咬牙切齿的时候,当我们也同样不认真的时候,我
们所做的又与他们有什么不同。所谓尊严,从来不是施舍,而是用血和汗水换来的。
ACM-ICPC, Changchun, China (4)














 .
.
pics








 .
.
羽传说.Unix
羽传说.Unix今何在先生在《羽传说》中说,"将来你们都死了,她还活着;鹤雪完了,她仍然
在;她不在了,她的名字仍然在;有她的名字,就有鹤雪。"我想,他提到的那个奇异女子的名字,应该是叫做...Unix。有位同学前几天来信,问我Ubuntu的学习入门捷径的参考书。我想了又想,最终
发现自己完全不能为力。推荐Linux类的快速入门,太难为我了。说实话,我从来
没有读过Linux使用的书,所以真是难以推荐。我在十多年前,读了一些Unix相关
的书,后来,一直只看手册,没看过书;Ubuntu安上就用了,没有学习过。1998年开始在图书馆工作,单位派我跟刘青华大侠去北京学习solaris下的
tcp/ip协议,那是我第一次开始使用unix。在那之前,约1996年,李金环老师的
同学李(我忘记这位大侠的全名了,他去了哈尔滨),他当时读物理系的研究生,
向我推荐过unix。他说:现在很多人在学习。当年年轻,我不装作很不在乎的样
子,说novell netware的功能也非常强大啊。这些年以后,netware退出了江
湖,unix的名字也很少有人提到,不过天下武功出unix,它后代的名号却不绝于
耳。其中一个是linux。还是去北京学tcp/ip那次,在中关材,刘大侠买了张slackware送我,那是我的第
一张linux光盘。后来芬兰的网管Micael问我,用Linux没问题吧。我说,约十年
前,我用slackware。他说:哈,第一代。linux后来还有很多代,很多不同的发行版本。但是,对于固守于传统的那些人,它
们的不同小得多。还是芬兰,Lilius教授问我,俺们都用Linux,你没问题吧。
我说:我以命令行为主。他就不担心了。命令行下的unix,那些小到微型的工具,却可以经脚本粘成方便的工具。这两天
又用了一下,过几天比赛结束了,再总结。主要是周期备份,周期上传用来发布
实时成绩,这样简单的功能。为什么没有使用更新一些的技术,比如python,比如java?这个问题可以用前几
天与林同学的一段对话来回答。林同学说:俄罗斯方块中有方块下落和旋转同时进行,这应该 (或者只能?)用
多线程来实现。如果不用多线程就不能实现这一功能了么?多线程是实现这一功能的首先方案么?首先,不用多线程仍然可以实现这一功能,即表面上看起来同时发生两件事。在
红白机时代,那么点内存和CPU的机器,根本就不应该有多线程支持,但是显然实
现了这样的功能。比如,有个方法非常朴素,就是在循环里先下落一行,然后旋
转。这两个动作不是同时发生的。其次,如果朴素的传统的方案能非常有效地解决某个问题,那么,当面临这个问
题时,如果没有足够的优势,我们不应该采用更新的方案。一方面,传统的方案
得到过检验,而新方案没有;另一方案,学习成本。可能有的同学会说,这太守旧了,新方案应该受到重视。是的,要不断尝试新的
东西,但不要在关键业务中,不要在真实的项目中测试尚不熟悉的技术。这跟药
物实验未完成前不能注射给病人是一个道理。所以,那些稳定的技术格外宝贵。很多技术在unix之后产生,然后衰败,而unix一直似乎就没有变过。想起有同学
提到,pc^2这东西不行啦,一个依据是它都N多年没更新了。这个判据不算好。不
再经常更新的东西有两种,一种是被淘汰将死了,还有一种是成熟了。李风华同学质问过,如果unix-like的方案这么好,为什么后来没有人用了呢?当
年我说:我也不清楚。现在,我能回答出两个方面:1.其实当时也仍然有非常多
的人用这一方案,或者这一方案的变型,只是我了解得太少,还不知道;2.很多
新一代,比如我,只知道那些新的技术,相信课本上提到某某技术 (比如面向对
象) 很牛,所以适用于各个领域。再回来看那么同学的诉求,这并不是孤例。我,你,很多人常常问出这样的问
题:怎么才能迅速地瘦下来/胖起来/提高学习成绩/健康/长肌肉/学会unix或
linux/学会编程……诸如此类。很多更有经验的人会告诉我们,答案是:不能。你不能迅速地实现实
些目标,除非你做假。Lilius说过,为了显得有肌肉,他听说过有人植入硅胶的
假肌肉。那是我第一次听说男士这种整容的。那些只能慢慢成长起来的东西,它们天生就不能迅速获得。就像你的想法,只有
自己的,才是自己的。灌输而来的,即使在体内,到底也只能是异物。成长,缓慢而痛苦。但正如牙齿,唯有缓慢,才能生长为我们的一部分,而不是
植入;正如牙齿,只有那些稳定而坚固的材料,才适宜,而五彩闪光,也许只能
装饰。"将来你们都死了,她还活着;鹤雪完了,她仍然在;她不在了,她的名字仍然
在;有她的名字,就有鹤雪。"她的名字是Unix。
瓶颈,及傍晚的一缕阳光
瓶颈,及傍晚的一缕阳光1. 流水线上午,某同学的项目,今天是装系统,我们去了好几个人。外面风沙非常大,风
大到我要倾斜着才能行走,沙子大到迷了好几次眼睛。我把冲锋衣上面的那个帽
子 (应该是hood,但是我怕李记者说我小资,所以这样写) 也套上,免得压在里
面的棒球帽被风吹跑了。到了里面,终于没有风,但是沙尘更大了。马上要运营了,仍在装修中。电锯
声,窄而陡的楼梯,昏暗的灯光,偶尔,有人的声音传来。像不像电锯杀人狂之
类恐怖片现场?其实,打CS也挺好,很多射击死角。他们把半座大厦里面架上了铁楼板,分成很
多层,楼层间是错综复杂的铁楼梯,踩上去当当响。在铁楼梯上七拐入拐,终于
到了某个房间,木头门玻璃墙,怡与一般的常理相反。此处楼板表面铺以非实木
地板,踩上去也当当响,说明下面很薄而且是空的。开始装系统。需要1.设置IP,2.分配IP和用途,3.安装系统并设置。很快发现需
要很长时间,有窝工的地方。最开始是装系统非常慢。刘同学尝试了不用U盘,而是通过网络从服务器复制安装
文件,速度还是慢;分配两个人装系统和设置,很快另一个有别的安排跑了。这时,流水线开始调整和形成。我们安排了一个人兼职向要安装的机器里复制安
装文件,并按刘同学的要求优化(并测试通过)了安装包的大小。我们安装了两个人专门分配IP和写标签,把标签贴在机器脑门 (还是后脑勺)上。
很快,IP和标签最先完成。这一任务既完,重新安排这两位的工作:一个人去参
与分配IP,调另一个人专职负责向机器里复制安装包。流水线于是大致形成,后来又有小的修改,于是形成下述格局。一位供应商女士负责开机,然后把机器开着盖交给黄同学,黄同学和另一位同学
设置IP,设备完成以后,供应商男士把机器传递到另一间屋子给杨同学,杨同学
复制安装包,然后把机器盖上堆在刘同学面前,刘同学和 (有时)网络管理员女士
安装并设置,设置的时候连接到服务器上测试网络及数据库连接,然后盖上盖,
供应商男士 (与前面提及的是同一位)把机器重新装箱。流水线一旦建立,不到一个小时,全部完成。这个故事告诉我们,流水线中至关重要的,是找到瓶颈所在。方法是看谁的面前
堆的机器最多,减少他的任务,把他的任务拆开分配给别人,优化他的任务速
度,增加他可能的并行。程序设计时,把查找瓶颈的工具称为 profile。应该优化的是,不是速度最慢的
部分,而是对系统整体速度影响最大的部分。2. 傍晚一缕阳光下午,讨论某项目,我迟到了半小时。非常抱歉。讨论完以后,去找向龙同学,他昨天提到java访问mysql数据库乱码问题。某同
学在清华大学呢,说网络巨慢,希望我参与。这个问题很快就解决了,我昨天晚
上猜测了一下大约可能的问题,在网上搜索了两个贴子,发到了自己的信箱里。
现场选了较简单的那个,改 mysql.ini 的 defualt charset 为 utf-8,好使了。除了在windows下,包括在java下,utf-8才是统一的标准。是不是有点像电子学
的图示,国标只有在上交报告时不得已才采用?以上问题没多大意思,有意思的是下一个。向龙说,同步某几个数据库的时候速
度慢,每天的数据需要七八分钟。他非常非常非常熟练地告诉我:从这个mysql数
据库里的这个表里查找这个字段,然后把这个字段按某哔哔哔[此处保密]的算法
进行转换,在这个sql server数据库里查找这个表里的这个字段,然后再把它它
它写到……我实在记不住的另一个数据库里。以上,是一个标准的流程,查查查,然后写。如果速度慢,问题可能在哪里呢?
每一步都有可能。我们要做的第一步是--绝不是查找哪一步慢,而是验证向龙说的是真的。我请他
同步某天的数据,我们用手机上的秒表掐时间。同时附加了一个小的验证实验。不带插入数据,2分40秒,带插入数据,2分20秒。
差不多。考虑到网页延迟,CPU分配不均啥的,应该就是一样了。那么,最后一
步插入并不是瓶颈。此时,我想到图书馆当年导出数据时的著名案例,200多个工作日的工作量变成
半个小时导完。详情请参见以前博客,不赘述。然后,我们开始新的验证实验。我请他,没错,我请向龙同学,而不是我自己,
因为我不会这些操作的步骤,我请向龙同学进行下述操作:把所有(两处)select
语句中的where子句中的所有字段设置为index。第一处,mysql那个,向龙自己已经加了index。我看了半天新新新版的
phpmyadmin,在向龙的指导下找到了索引,我上次用它是十年前?第二处,sql server那个,加索引的时候提醒我们,改库结构可能会花很长时间。
然后,瞬间就加完了。不知道是机器太快了还是怎么的,按说库应该不小啊。当
年图书馆那四十多万种图书的记录加索引花了2个小时还是多长时间来着。加完索引以后,我们重复导出的实验。20秒。换一天,还是20秒。再换一天,很
长很长时间没反应,但是向龙查库结构已经导完了。再换一天,还是20秒。后来
我们估且认为,那次时间特别长的,是程序出了毛病。我坐在向龙的旁边,等二猫放学。午后,接近傍晚的阳光斜着从南面的窗子里射
在他的桌子上,很温暖。桌子是暗黄色的木纹,上面放着一个透明的水瓶,里面
几枝植物绿色黄色的根茎。阳光穿透这些根茎投射在桌面的木纹上,光影交错。有一缕阳光,正好射在我的眼睛里,那是瓶底附近的一小块光斑。周围的一切都
隐在暗淡里,向龙哗哗敲着键盘导这个那个数据,他对面的女士一边查着新的机
动车限行规定一边出声地思考。所有这些都模糊了,只有那一缕阳光分外清晰。我拿相机拍下来,说这个太漂亮了,就从我刚刚坐着的那个角度看。向龙说,啊
呀,是挺漂亮,我一直坐在这里都没注意到,就在我显示器后面。我说:就是因为你一直坐在那吧。向龙说:你还有精神头整这个呐。我说:兄弟,如果没有这个,我不知道还能不能活下去了。如果身处流水线中,一个又一个的瓶颈,看不到未来。你会不会绝望?那一缕阳
光,就是唯一的安慰了,存在,真实,温暖。最近在看《哥德尔 艾舍尔 巴赫》。作者说,人都生存于一个系统之中,很多人
花费大量的时间就是为了认识到或说服别人,这样一个系统的存在,然后从系统
中摆脱出来。超越自己存在于其中的,又谈何容易?虽然,跳开去看,像赵元良
老师教导我的,那些小事,又都算得了什么。诚然如此,可是问题又回来了,如
何跳开去呢,向哪个方向?前路漫漫,估且欣赏这一缕阳光吧。
pics





 .
.
泰坦尼克 (有剧透)
泰坦尼克 (有剧透)据说上次泰坦尼克流行是十五年前?具体的时候我早就不记得了,只记得那个时
候,文艺青年们更喜欢把它称为《铁达尼号》,似乎不这样不足以表明自己紧跟
时代的潮流。现如今,网络中似乎没有哪个文艺+1的青年会再提铁达尼了,香港
和台湾都out了,当今世界,英剧和美剧才能彰显他们与众不同。但是核心的道理从来也没有变过,追随大潮,以证明我们的存在--同时还要高
喊,我们如此与众不同。当年我就不怎待见罗丝他们俩,我指的是罗丝和杰克,还有过颇有过一些争论。
我不待见他们的原因,到现在也没有变化。1. 罗丝老太太后来扔海里的那块大钻石,就是年轻罗丝在片子里一直戴着的那
个海洋之心,它的所有权无疑是罗丝的未婚夫的。没错,这是罗丝未婚夫送给罗
丝的,但是该赠予有明确的条件,即罗丝要嫁给这位绅士。既然罗丝不打算屡行
条约,那么应该把海洋之心还给人家。有人说,那是爱情还是什么的见证,还有
什么乱七八糟的理由,比如那东西真好爱呐啥的,都改变不了一个事实,那东
西,它是罗丝未婚夫的。无论有多么充分的理由,你都没有权利剥夺别人的东
西,尤其留给了自己。2. 罗丝和杰克未来的日子真是令人担心。如果泰坦尼克不是幸好 (或不幸)撞了
冰山,如果这两位真的到了纽约,问题就来了。他们的未来生活会是啥样的?罗
丝,大家闺秀,只会偶尔装一下反叛;他的新未婚示杰克,是一个不得志的画
家,会画裸女。无疑的,罗丝没啥谋生能力,如果离开父母的荫弊的话。也许,
她的欧洲史或者古拉丁文不错,还能在沙龙里讨论新番动漫里哪个人物最萌,但
是,看起来她缺乏基本的工程素养,不能做工程师或者技术工人,所以,她最可
能的职业是当女佣。那个时代当女佣还不太需要职业资格认证。杰克呢,他老
婆,就是罗丝,肯定不能同意他以画裸女为生。画自己是一艺术,而绝非色情,
画别人,那就是另一回事了。那个时候开班授课高考美术加试估计也还不流行,
所以,杰克估计可以去车间铲煤。铲煤,就是他们非常浪漫地在泰坦尼克号的底
舱穿行,边儿上全是红火碳,罗丝的前未婚夫搁后面狂追,此时周围那一群被观
众你一扫而过的黑乎乎的工人。非技术类的。杰克得到这一工作的好处是,他后
来的胸大肌和背阔肌都会发达起来,就比较像个爷们了。综上所述,罗丝不该偷或抢别人的珠宝,同时,她和杰克的未来堪忧。所以,我
为他们想到了一个出路。他们极可能会把海洋之心卖了,这样就能过上幸福的美
国生活了。那么为什么大家还这么喜欢这部分片子呢?当然,许多成年人和男性对这部片子
不太喜欢,原因一会再说。为什么某些大家喜欢这部片子呢。她们幻想自己没有从了 (或者将从了) 高帅
富,而是跟随了心中的那个人,这非常令人向往。但是她们中的许多 (?) 最终
并没有遵从自己的幻想,又或者此时她们就已经认识到自己将不遵从自己的幻
想,而是将把它像童话一样抛开,所以此片略可弥补这一遗憾。另一小撮为什么不喜欢这片子呢,尤其是在他们大多数事情都三从四德的时候?
因为他们看到了片子里的至理:部分女人所跟从的是海洋之心--如果想浪漫,要
么,像杰克一样短暂的,要么,比较正统而长久的,作为高帅富,这样就有了浪
漫的资本。兄弟们最终从片子每祯的黑色间隙里看到了自己被期待成为的那个
人,浪漫的高帅富。潜台词是,你要么成为这个人,要么,淹死得了。所以,泰坦尼克的大热表明女性已经取得了独立的经济权利以后,艺术家们终于
拍出了她们想要的东西。就像男性有独立的经济权,所以看看几千年来艺术家们
整出的都是些什么男性喜欢的玩意。估计不少同学都要跳起脚来叫:我才不是那样呢。当然,你才不是呢,我说的根
本就不是可爱智慧优秀的你。恩,还有浪漫而帅气,优雅而那啥。我们属于另一拨人,超出性别以外的。半个月还是一个月以前,在KFC吃饭的时候,同学们讲他们都在看什么书。郑蕊同
学在看 龙书,就是编译原理;刘鹏同学刚看完黑客与画家,正看人月神话,英文
笔记写了40多页,而且工整,让我顿时肃然起敬;张健同学正看沈良的《时间
》,哲学的。他们都是计算机研究生。为什么我要提这件事呢?因为他读这些书都是不是被迫
的,而是自发自愿,怀着吉悦的心情去读的。当然,凡事用功到一定程度,没有
不被累得吐舌头的,即使你非常非常擅长这事。莫扎特小时候似乎练钢琴经常被
他老爸揍得直哭。我初中有位张同学,学过散打。他及其同学们在最后一课把教
他们散打得老师揍得直跑,最后不得不亮出匕首。这两个故事告诉我们,无论你
多么喜欢,过程可能都是苦的。然后,关键在于,那些苦都是你自动自觉去品尝
的。如果是这样,那么,你还没有忘记你的理想。我想对罗丝说,不要偷了别人的钻
石,还抹着眼泪好像自己多么纯情,说这记忆了你人生重要的经历什么的。把海
洋之心摔回那谁的手里,然后跟着杰克一起跳到海里去死。我的理想,根本不需要某部片子的认同,甚至不需要拿出来与你分享。我的理
想,就是我每一天在做的那些事情。又及。如果我是罗丝,在杰克说"你跳我也跳"的时候,一定会问,"你我素不相
识的,你有什么企图?"
pics




 .
.
当老师布置了错误的实验作业
当老师布置了错误的实验作业昨天看了《生活大爆炸》,Sheldon遇到霍金。一大清早我做梦。说我给学生布置完实验作业,回家一演算,坏了,原理错误,实验根据做不出来。
第二天一看大家的实验报告,全做出来了。某大的同学说:猜到你这猪头把实验设计错了,所以我把实验数据改了,这样报告做出来了。北大的同学说:猜到你这猪头把实验设计错了,所以我把实验原理改了,这样实验做出来了。清华的同学说:猜到你这猪头把实验设计错了,所以我把宇宙参数改了,这样实验做出来了。阿于同学突然跳出来说,那科大呢?我说:你在美国好好待着得了,回来干啥,一边呆着去。然后,去年见到的刘同学跳出说,那交大呢,很多年没见的徐同学跳出来说,那
国防科大呢?我说:你们考那么好的大学,今天全是蹦回来特意打击我的么。后来,醒了直乐。我怎么变成了齐同学一样的小愤愤了呢。反正大家都有办法把
报告搞出来,好好工作吧。